Tunnel Try-on: Excavating Spatial-temporal Tunnels for High-quality Virtual Try-on in Videos
2404.17571
3
0
Abstract
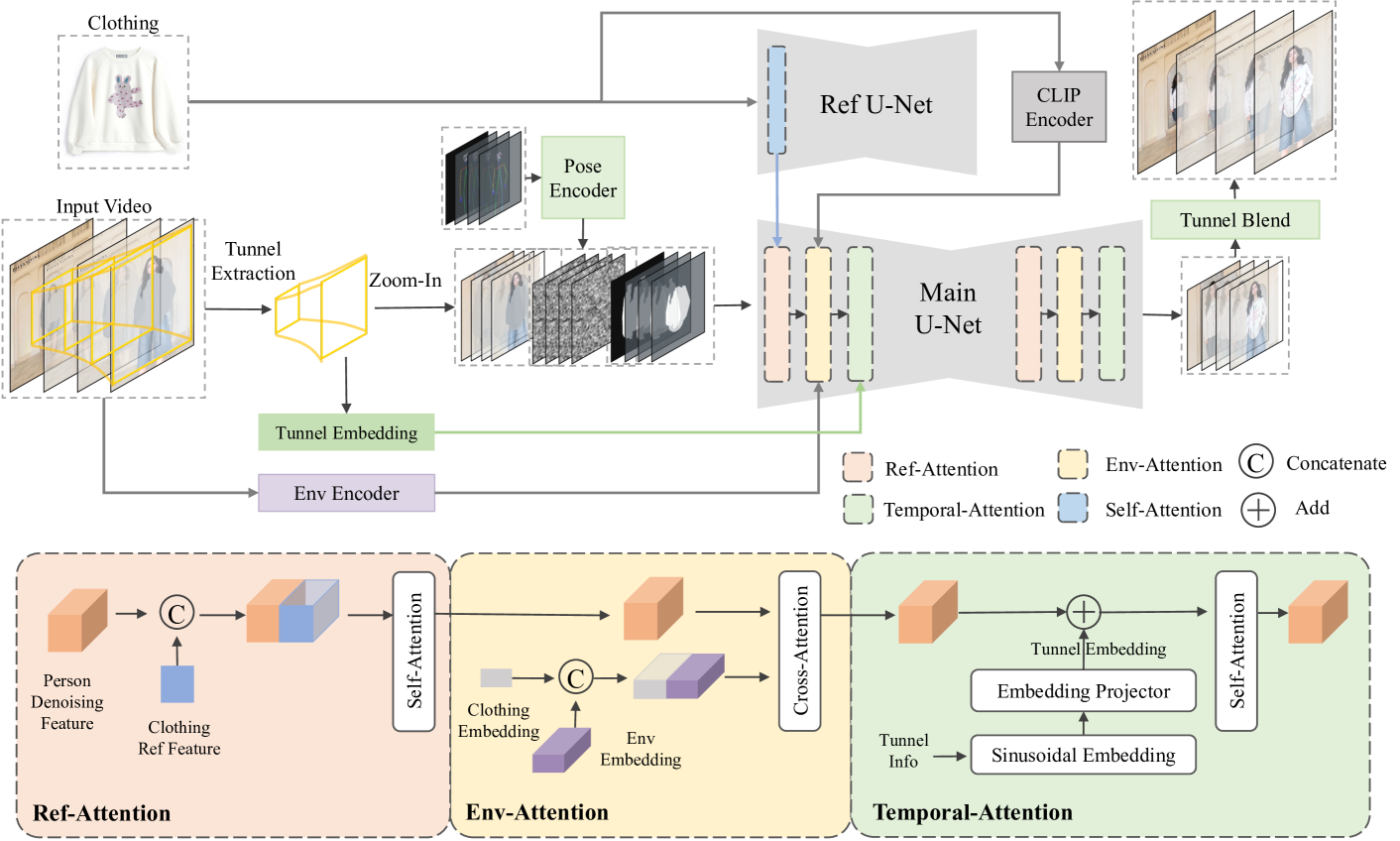
Video try-on is a challenging task and has not been well tackled in previous works. The main obstacle lies in preserving the details of the clothing and modeling the coherent motions simultaneously. Faced with those difficulties, we address video try-on by proposing a diffusion-based framework named Tunnel Try-on. The core idea is excavating a focus tunnel in the input video that gives close-up shots around the clothing regions. We zoom in on the region in the tunnel to better preserve the fine details of the clothing. To generate coherent motions, we first leverage the Kalman filter to construct smooth crops in the focus tunnel and inject the position embedding of the tunnel into attention layers to improve the continuity of the generated videos. In addition, we develop an environment encoder to extract the context information outside the tunnels as supplementary cues. Equipped with these techniques, Tunnel Try-on keeps the fine details of the clothing and synthesizes stable and smooth videos. Demonstrating significant advancements, Tunnel Try-on could be regarded as the first attempt toward the commercial-level application of virtual try-on in videos.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces "Tunnel Try-on", a novel approach for high-quality virtual try-on in videos.
- The key idea is to "excavate" spatial-temporal tunnels that capture the clothing and body shape of the user, allowing for seamless virtual try-on.
- The method leverages diffusion models to generate high-fidelity try-on results, addressing limitations of prior work like MV-VTON, Street-TryOn, and CAT-DM.
Plain English Explanation
The paper presents a new way to virtually try on clothes in videos. The key idea is to create "tunnels" that capture the 3D shape of the person's body and the clothing item over time. These tunnels allow the system to seamlessly insert the new clothing onto the person in the video, producing high-quality results.
Prior virtual try-on methods struggled with issues like distortion, lack of temporal consistency, and the need for specialized cameras. The "Tunnel Try-on" approach using diffusion models addresses these limitations, enabling more natural and realistic virtual clothing try-on in regular videos.
Technical Explanation
The paper introduces the "Tunnel Try-on" framework, which aims to address the challenges of previous virtual try-on methods like MV-VTON, Street-TryOn, and CAT-DM.
The key innovation is the use of spatial-temporal "tunnels" that capture the 3D shape of the person and clothing item over time. These tunnels are then used to guide a diffusion model in generating high-fidelity try-on results, preserving temporal consistency and avoiding distortion.
The authors propose a multi-stage pipeline that first extracts the 3D body and clothing shapes, then uses these to create the spatial-temporal tunnels. A diffusion model is then trained to generate the final try-on output, conditioned on the tunnels and input video.
Extensive experiments demonstrate the superiority of Tunnel Try-on over prior methods, achieving state-of-the-art virtual try-on quality and temporal stability on various benchmarks.
Critical Analysis
The paper presents a compelling approach to addressing the limitations of existing virtual try-on methods. The use of spatial-temporal tunnels is a novel and promising idea that allows the system to maintain temporal consistency and generate high-quality try-on results.
However, the paper does not discuss the computational complexity or real-time performance of the Tunnel Try-on framework. Given the need for 3D shape extraction and diffusion model inference, there may be challenges in deploying this system for immediate practical applications.
Additionally, the paper focuses on a single clothing category (upper-body garments) and does not explore the ability to handle more diverse clothing types, such as lower-body items or accessories. Further research may be needed to evaluate the generalizability of the approach.
Overall, the Tunnel Try-on method represents an important advance in the field of virtual try-on, particularly in its ability to preserve temporal coherence and produce realistic results. The technical innovations and insights provided in this paper are valuable contributions that warrant further exploration and refinement.
Conclusion
The "Tunnel Try-on" paper introduces a novel approach for high-quality virtual try-on in videos. By leveraging spatial-temporal "tunnels" to capture the 3D shape of the user and clothing, the method is able to generate realistic and temporally consistent try-on results using diffusion models.
This work addresses key limitations of prior virtual try-on methods, such as distortion, lack of temporal stability, and the need for specialized camera setups. The technical innovations and strong experimental results presented in this paper represent an important step forward in the field of virtual clothing try-on, with potential applications in e-commerce, fashion, and beyond.
While further research is needed to address practical deployment challenges and expand the clothing types supported, the Tunnel Try-on framework demonstrates the power of combining spatial-temporal shape modeling with advanced generative techniques to enable more immersive and realistic virtual try-on experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
Image-Based Virtual Try-On: A Survey
Dan Song, Xuanpu Zhang, Juan Zhou, Weizhi Nie, Ruofeng Tong, Mohan Kankanhalli, An-An Liu
0
0
Image-based virtual try-on aims to synthesize a naturally dressed person image with a clothing image, which revolutionizes online shopping and inspires related topics within image generation, showing both research significance and commercial potential. However, there is a gap between current research progress and commercial applications and an absence of comprehensive overview of this field to accelerate the development. In this survey, we provide a comprehensive analysis of the state-of-the-art techniques and methodologies in aspects of pipeline architecture, person representation and key modules such as try-on indication, clothing warping and try-on stage. We propose a new semantic criteria with CLIP, and evaluate representative methods with uniformly implemented evaluation metrics on the same dataset. In addition to quantitative and qualitative evaluation of current open-source methods, unresolved issues are highlighted and future research directions are prospected to identify key trends and inspire further exploration. The uniformly implemented evaluation metrics, dataset and collected methods will be made public available at https://github.com/little-misfit/Survey-Of-Virtual-Try-On.
5/2/2024
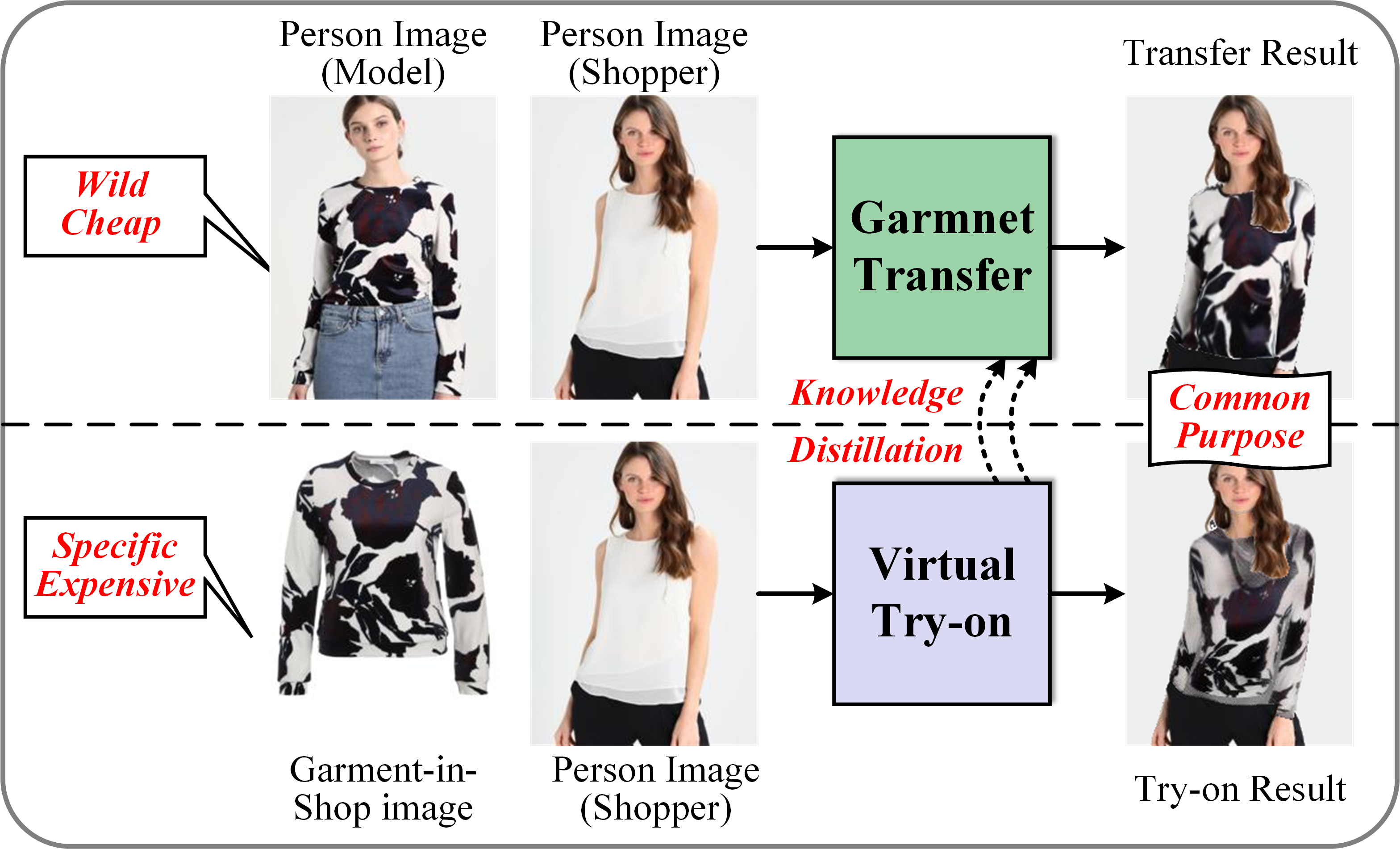
A Novel Garment Transfer Method Supervised by Distilled Knowledge of Virtual Try-on Model
Naiyu Fang, Lemiao Qiu, Shuyou Zhang, Zili Wang, Kerui Hu, Jianrong Tan
0
0
This paper proposes a novel garment transfer method supervised with knowledge distillation from virtual try-on. Our method first reasons the transfer parsing to provide shape prior to downstream tasks. We employ a multi-phase teaching strategy to supervise the training of the transfer parsing reasoning model, learning the response and feature knowledge from the try-on parsing reasoning model. To correct the teaching error, it transfers the garment back to its owner to absorb the hard knowledge in the self-study phase. Guided by the transfer parsing, we adjust the position of the transferred garment via STN to prevent distortion. Afterward, we estimate a progressive flow to precisely warp the garment with shape and content correspondences. To ensure warping rationality, we supervise the training of the garment warping model using target shape and warping knowledge from virtual try-on. To better preserve body features in the transfer result, we propose a well-designed training strategy for the arm regrowth task to infer new exposure skin. Experiments demonstrate that our method has state-of-the-art performance compared with other virtual try-on and garment transfer methods in garment transfer, especially for preserving garment texture and body features.
4/5/2024
🏅
MV-VTON: Multi-View Virtual Try-On with Diffusion Models
Haoyu Wang, Zhilu Zhang, Donglin Di, Shiliang Zhang, Wangmeng Zuo
0
0
The goal of image-based virtual try-on is to generate an image of the target person naturally wearing the given clothing. However, most existing methods solely focus on the frontal try-on using the frontal clothing. When the views of the clothing and person are significantly inconsistent, particularly when the person's view is non-frontal, the results are unsatisfactory. To address this challenge, we introduce Multi-View Virtual Try-ON (MV-VTON), which aims to reconstruct the dressing results of a person from multiple views using the given clothes. On the one hand, given that single-view clothes provide insufficient information for MV-VTON, we instead employ two images, i.e., the frontal and back views of the clothing, to encompass the complete view as much as possible. On the other hand, the diffusion models that have demonstrated superior abilities are adopted to perform our MV-VTON. In particular, we propose a view-adaptive selection method where hard-selection and soft-selection are applied to the global and local clothing feature extraction, respectively. This ensures that the clothing features are roughly fit to the person's view. Subsequently, we suggest a joint attention block to align and fuse clothing features with person features. Additionally, we collect a MV-VTON dataset, i.e., Multi-View Garment (MVG), in which each person has multiple photos with diverse views and poses. Experiments show that the proposed method not only achieves state-of-the-art results on MV-VTON task using our MVG dataset, but also has superiority on frontal-view virtual try-on task using VITON-HD and DressCode datasets. Codes and datasets will be publicly released at https://github.com/hywang2002/MV-VTON .
4/30/2024
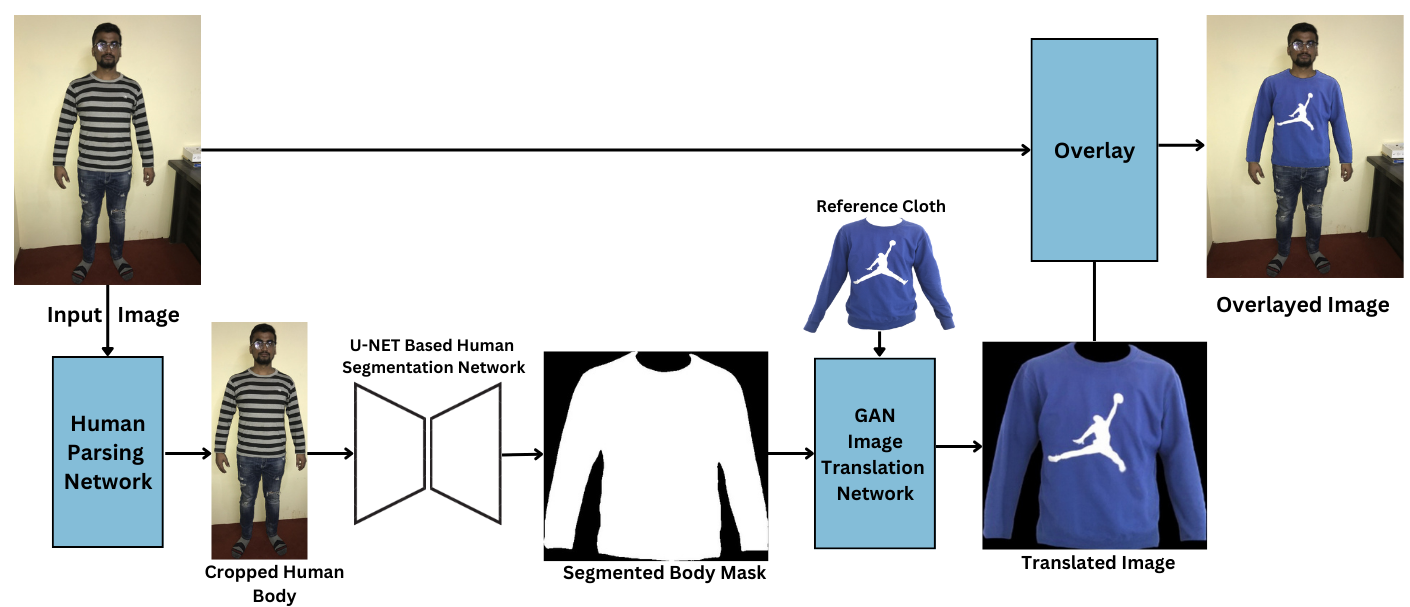
VTON-IT: Virtual Try-On using Image Translation
Santosh Adhikari, Bishnu Bhusal, Prashant Ghimire, Anil Shrestha
0
0
Virtual Try-On (trying clothes virtually) is a promising application of the Generative Adversarial Network (GAN). However, it is an arduous task to transfer the desired clothing item onto the corresponding regions of a human body because of varying body size, pose, and occlusions like hair and overlapped clothes. In this paper, we try to produce photo-realistic translated images through semantic segmentation and a generative adversarial architecture-based image translation network. We present a novel image-based Virtual Try-On application VTON-IT that takes an RGB image, segments desired body part, and overlays target cloth over the segmented body region. Most state-of-the-art GAN-based Virtual Try-On applications produce unaligned pixelated synthesis images on real-life test images. However, our approach generates high-resolution natural images with detailed textures on such variant images.
5/8/2024