Step Differences in Instructional Video
2404.16222
15
0

Abstract
Comparing a user video to a reference how-to video is a key requirement for AR/VR technology delivering personalized assistance tailored to the user's progress. However, current approaches for language-based assistance can only answer questions about a single video. We propose an approach that first automatically generates large amounts of visual instruction tuning data involving pairs of videos from HowTo100M by leveraging existing step annotations and accompanying narrations, and then trains a video-conditioned language model to jointly reason across multiple raw videos. Our model achieves state-of-the-art performance at identifying differences between video pairs and ranking videos based on the severity of these differences, and shows promising ability to perform general reasoning over multiple videos.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper investigates the differences in step-by-step instructional videos, with a focus on understanding how the level of detail and the pacing of instructions can impact learning.
- The researchers analyze a dataset of instructional videos across various domains, such as cooking, crafting, and home repair, to identify patterns in the way instructions are presented.
- The goal is to gain insights that can inform the design of more effective instructional videos and enhance learning experiences for viewers.
Plain English Explanation
The paper examines how the step-by-step instructions in educational videos can differ in terms of the level of detail and the pace at which they are presented. By analyzing a collection of instructional videos across various topics, such as cooking, crafting, and home repairs, the researchers aim to identify patterns and insights that can help create more effective and engaging instructional videos.
The idea is that the way instructions are presented in these videos can have a significant impact on how well viewers are able to learn and follow the steps. Some videos might provide a lot of detailed information, while others might move through the steps more quickly. The researchers want to understand these differences and how they affect the learning process.
By uncovering these patterns, the researchers hope to provide guidance on how to design instructional videos that are more tailored to the needs of the viewers, helping them learn and retain the information more effectively. This could have applications in a wide range of educational and training contexts, from cooking classes to DIY tutorials.
Technical Explanation
The paper Distilling Vision-Language Models from Millions of Videos analyzes a dataset of instructional videos to investigate the differences in the way step-by-step instructions are presented. The researchers examine factors such as the level of detail provided in each step and the pacing of the instructions.
The analysis is conducted across a diverse set of instructional video domains, including cooking, crafting, and home repair. By identifying patterns in how instructions are delivered, the researchers aim to provide insights that can inform the design of more effective instructional videos. This aligns with related work on Generating Illustrated Instructions, Improving Interpretable Embeddings for Ad-Hoc Video Search, and Improving Video-Text Retrieval through Augmentation, which also explore ways to enhance the learning and information delivery in instructional media.
The key objective is to understand how the presentation of step-by-step instructions in videos can impact the viewers' ability to learn and retain the information. By uncovering these patterns, the researchers hope to provide guidelines and design principles that can lead to the creation of more effective and engaging instructional videos, ultimately improving the learning experiences for viewers.
Critical Analysis
The paper presents a comprehensive analysis of step differences in instructional videos, which is a valuable contribution to the field of video-based learning and instruction. However, the study is limited to a specific set of video domains, and it would be interesting to see if the identified patterns hold true across a wider range of instructional content.
Additionally, the paper does not delve into the potential cognitive and psychological factors that may influence how learners respond to different levels of detail and pacing in instructional videos. Incorporating insights from educational psychology and human learning research could further strengthen the implications and practical applications of the findings.
It would also be worthwhile to explore how factors such as the viewers' prior knowledge, learning styles, and personal preferences might interact with the presentation of step-by-step instructions. This could help identify more nuanced design guidelines that account for individual differences among learners.
Conclusion
This paper provides valuable insights into the differences in step-by-step instructional videos, highlighting the importance of understanding how the level of detail and pacing of instructions can impact learning. The findings can inform the design of more effective instructional videos, contributing to enhanced learning experiences across a variety of educational and training contexts.
By uncovering patterns in the way instructions are presented, the researchers lay the groundwork for developing design principles and guidelines that can guide the creation of instructional videos that are tailored to the needs and preferences of viewers. This research has the potential to positively impact the way educational and training content is delivered, ultimately improving learner outcomes and engagement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
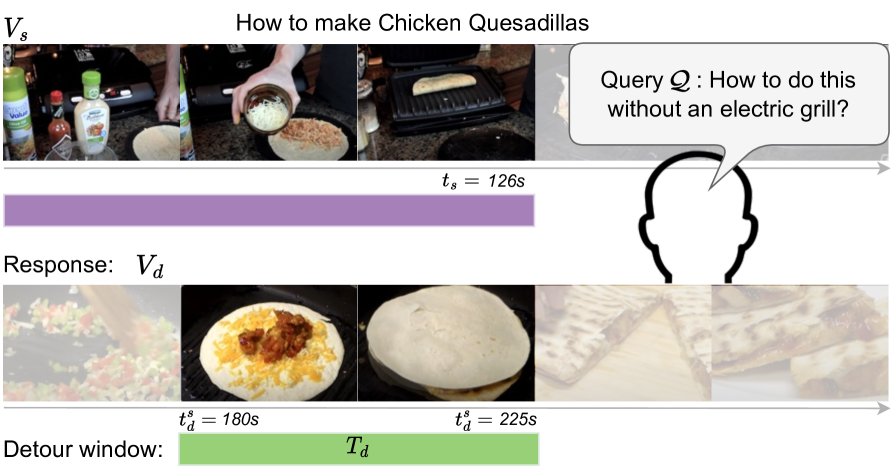
Detours for Navigating Instructional Videos
Kumar Ashutosh, Zihui Xue, Tushar Nagarajan, Kristen Grauman
0
0
We introduce the video detours problem for navigating instructional videos. Given a source video and a natural language query asking to alter the how-to video's current path of execution in a certain way, the goal is to find a related ''detour video'' that satisfies the requested alteration. To address this challenge, we propose VidDetours, a novel video-language approach that learns to retrieve the targeted temporal segments from a large repository of how-to's using video-and-text conditioned queries. Furthermore, we devise a language-based pipeline that exploits how-to video narration text to create weakly supervised training data. We demonstrate our idea applied to the domain of how-to cooking videos, where a user can detour from their current recipe to find steps with alternate ingredients, tools, and techniques. Validating on a ground truth annotated dataset of 16K samples, we show our model's significant improvements over best available methods for video retrieval and question answering, with recall rates exceeding the state of the art by 35%.
5/7/2024

Distilling Vision-Language Models on Millions of Videos
Yue Zhao, Long Zhao, Xingyi Zhou, Jialin Wu, Chun-Te Chu, Hui Miao, Florian Schroff, Hartwig Adam, Ting Liu, Boqing Gong, Philipp Krahenbuhl, Liangzhe Yuan
0
0
The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video model by video-instruction-tuning (VIIT) is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%. As a side product, we generate the largest video caption dataset to date.
4/17/2024
🌀
New!Language-Guided Self-Supervised Video Summarization Using Text Semantic Matching Considering the Diversity of the Video
Tomoya Sugihara, Shuntaro Masuda, Ling Xiao, Toshihiko Yamasaki
0
0
Current video summarization methods primarily depend on supervised computer vision techniques, which demands time-consuming manual annotations. Further, the annotations are always subjective which make this task more challenging. To address these issues, we analyzed the feasibility in transforming the video summarization into a text summary task and leverage Large Language Models (LLMs) to boost video summarization. This paper proposes a novel self-supervised framework for video summarization guided by LLMs. Our method begins by generating captions for video frames, which are then synthesized into text summaries by LLMs. Subsequently, we measure semantic distance between the frame captions and the text summary. It's worth noting that we propose a novel loss function to optimize our model according to the diversity of the video. Finally, the summarized video can be generated by selecting the frames whose captions are similar with the text summary. Our model achieves competitive results against other state-of-the-art methods and paves a novel pathway in video summarization.
5/16/2024
⚙️
Generating Illustrated Instructions
Sachit Menon, Ishan Misra, Rohit Girdhar
0
0
We introduce the new task of generating Illustrated Instructions, i.e., visual instructions customized to a user's needs. We identify desiderata unique to this task, and formalize it through a suite of automatic and human evaluation metrics, designed to measure the validity, consistency, and efficacy of the generations. We combine the power of large language models (LLMs) together with strong text-to-image generation diffusion models to propose a simple approach called StackedDiffusion, which generates such illustrated instructions given text as input. The resulting model strongly outperforms baseline approaches and state-of-the-art multimodal LLMs; and in 30% of cases, users even prefer it to human-generated articles. Most notably, it enables various new and exciting applications far beyond what static articles on the web can provide, such as personalized instructions complete with intermediate steps and pictures in response to a user's individual situation.
4/16/2024