RAGCache: Efficient Knowledge Caching for Retrieval-Augmented Generation
2404.12457
32
1
Abstract
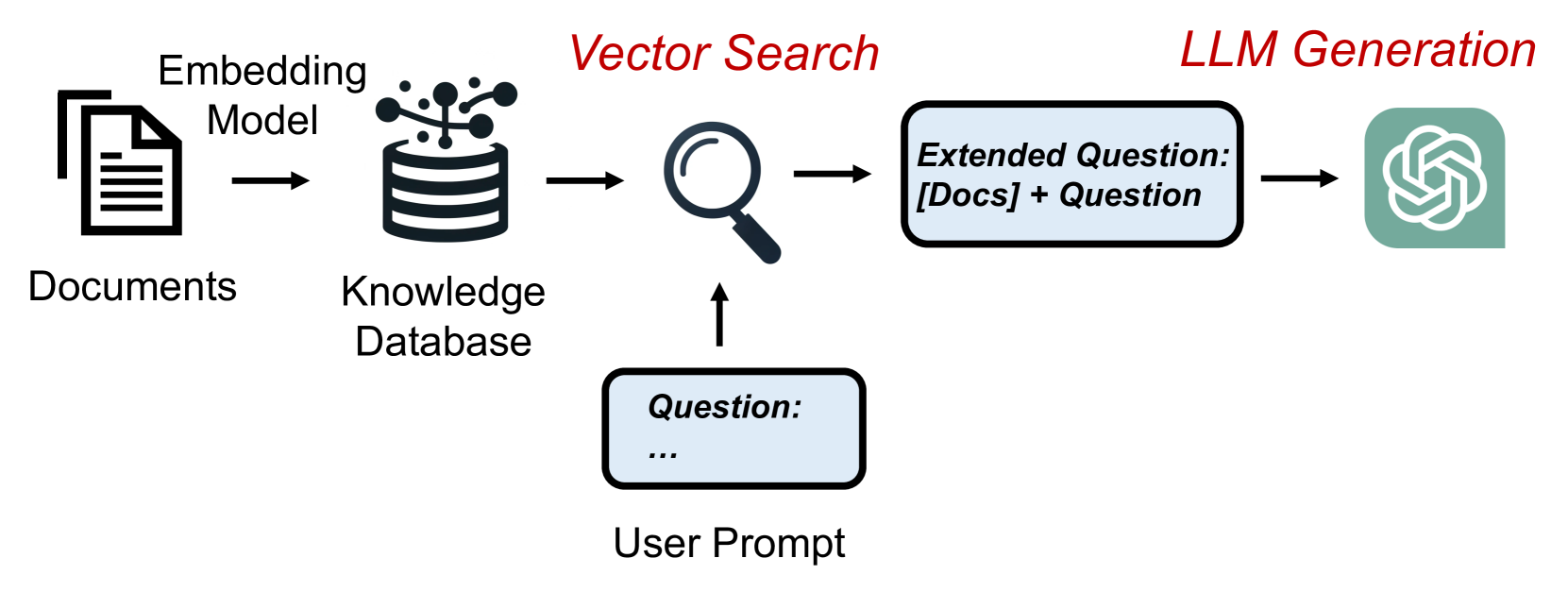
Retrieval-Augmented Generation (RAG) has shown significant improvements in various natural language processing tasks by integrating the strengths of large language models (LLMs) and external knowledge databases. However, RAG introduces long sequence generation and leads to high computation and memory costs. We propose RAGCache, a novel multilevel dynamic caching system tailored for RAG. Our analysis benchmarks current RAG systems, pinpointing the performance bottleneck (i.e., long sequence due to knowledge injection) and optimization opportunities (i.e., caching knowledge's intermediate states). Based on these insights, we design RAGCache, which organizes the intermediate states of retrieved knowledge in a knowledge tree and caches them in the GPU and host memory hierarchy. RAGCache proposes a replacement policy that is aware of LLM inference characteristics and RAG retrieval patterns. It also dynamically overlaps the retrieval and inference steps to minimize the end-to-end latency. We implement RAGCache and evaluate it on vLLM, a state-of-the-art LLM inference system and Faiss, a state-of-the-art vector database. The experimental results show that RAGCache reduces the time to first token (TTFT) by up to 4x and improves the throughput by up to 2.1x compared to vLLM integrated with Faiss.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces RAGCache, a new method for efficiently caching and retrieving knowledge in retrieval-augmented generation (RAG) models.
- RAG models combine a language model with a retrieval system to generate text that is grounded in external knowledge.
- RAGCache aims to improve the efficiency of RAG models by caching retrieved information and intelligently reusing it across multiple generations.
Plain English Explanation
RAG models are a type of AI system that can generate text by combining a language model (which understands and generates human-like text) with a retrieval system (which can find relevant information from a large knowledge base). This allows the model to generate text that is grounded in real-world knowledge, rather than just generating something completely made up.
However, the process of retrieving information from the knowledge base can be computationally expensive, especially if the model needs to do it repeatedly during the text generation process. The RAGCache technique introduced in this paper aims to make this process more efficient by caching the retrieved information and reusing it where possible.
The key idea is that if the model needs to generate text about a certain topic, it can first check if it has already retrieved relevant information about that topic and stored it in its cache. If so, it can simply reuse that cached information instead of doing an expensive new retrieval. This can significantly speed up the overall text generation process.
The paper explores different strategies for deciding what information to cache and how to efficiently manage the cache to get the most benefit. The authors show that RAGCache can improve the performance of RAG models on a variety of text generation tasks, making them faster and more efficient without sacrificing the quality of the generated text.
Technical Explanation
RAG models combine a language model, which is trained to generate human-like text, with a retrieval system, which can find relevant information from a large knowledge base. This allows the model to ground its text generation in real-world facts and knowledge, rather than just generating text based on patterns in the training data.
The key innovation of RAGCache is to introduce a caching mechanism to improve the efficiency of this retrieval process. When the RAG model needs to generate text, it first checks if the relevant information has already been retrieved and stored in the cache. If so, it can reuse the cached information instead of doing a new, expensive retrieval from the knowledge base.
The paper explores different cache management strategies, such as:
- Caching based on generation context: Caching information that is relevant to the current generation context, rather than caching everything.
- Caching based on retrieval quality: Caching only the most relevant and high-quality retrieved information.
- Intelligent cache replacement: Replacing less useful cached information with new, more relevant data as the cache fills up.
Through experiments on various text generation tasks, the authors show that RAGCache can significantly improve the efficiency of RAG models without sacrificing the quality of the generated text. By intelligently caching and reusing retrieved knowledge, RAGCache reduces the computational cost of the retrieval process, making RAG models faster and more practical to deploy.
Critical Analysis
The RAGCache approach presented in this paper is a promising step towards making retrieval-augmented generation models more efficient and practical for real-world applications. By caching retrieved information and reusing it intelligently, the authors demonstrate that RAG models can generate high-quality text while incurring lower computational costs.
However, the paper does not extensively explore the limitations or potential issues with the RAGCache approach. For example, it's unclear how the caching strategies would perform in domains with rapidly changing or constantly evolving knowledge, where the cached information may quickly become outdated or irrelevant.
Additionally, the paper does not discuss the potential privacy or security implications of caching large amounts of retrieved information, which could potentially expose sensitive or personal data. Unlocking Multi-View Insights for Knowledge-Dense Retrieval addresses some of these concerns, but further research is needed to fully understand the risks and mitigate them.
Overall, the RAGCache technique represents an important step forward in making retrieval-augmented generation more efficient and practical. However, future research should explore the limitations of the approach, as well as potential risks and ways to address them, to ensure that RAG models can be deployed safely and responsibly.
Conclusion
This paper introduces RAGCache, a new method for efficiently caching and retrieving knowledge in retrieval-augmented generation (RAG) models. RAG models combine a language model with a retrieval system to generate text that is grounded in external knowledge, but the retrieval process can be computationally expensive.
RAGCache aims to improve the efficiency of RAG models by caching retrieved information and intelligently reusing it across multiple generations. The authors explore different caching strategies and show that RAGCache can significantly improve the performance of RAG models on a variety of text generation tasks, making them faster and more efficient without sacrificing the quality of the generated text.
While the RAGCache approach is a promising step forward, the paper does not fully address potential limitations or risks, such as the challenges of dealing with rapidly changing knowledge or the privacy implications of caching large amounts of retrieved data. Future research should explore these issues to ensure that RAG models can be deployed safely and responsibly.
Overall, the RAGCache technique represents an important contribution to the field of retrieval-augmented generation, demonstrating how caching and reusing knowledge can make these powerful models more practical and efficient for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Introducing Super RAGs in Mistral 8x7B-v1
Ayush Thakur, Raghav Gupta
0
0
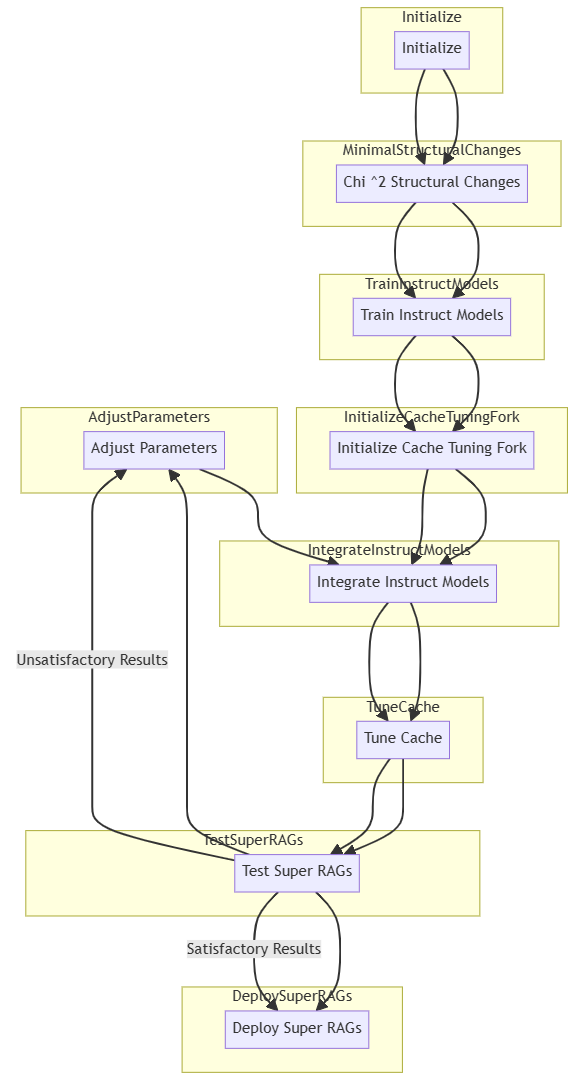
The relentless pursuit of enhancing Large Language Models (LLMs) has led to the advent of Super Retrieval-Augmented Generation (Super RAGs), a novel approach designed to elevate the performance of LLMs by integrating external knowledge sources with minimal structural modifications. This paper presents the integration of Super RAGs into the Mistral 8x7B v1, a state-of-the-art LLM, and examines the resultant improvements in accuracy, speed, and user satisfaction. Our methodology uses a fine-tuned instruct model setup and a cache tuning fork system, ensuring efficient and relevant data retrieval. The evaluation, conducted over several epochs, demonstrates significant enhancements across all metrics. The findings suggest that Super RAGs can effectively augment LLMs, paving the way for more sophisticated and reliable AI systems. This research contributes to the field by providing empirical evidence of the benefits of Super RAGs and offering insights into their potential applications.
4/16/2024
🛸
Robust Implementation of Retrieval-Augmented Generation on Edge-based Computing-in-Memory Architectures
Ruiyang Qin, Zheyu Yan, Dewen Zeng, Zhenge Jia, Dancheng Liu, Jianbo Liu, Zhi Zheng, Ningyuan Cao, Kai Ni, Jinjun Xiong, Yiyu Shi
0
0
Large Language Models (LLMs) deployed on edge devices learn through fine-tuning and updating a certain portion of their parameters. Although such learning methods can be optimized to reduce resource utilization, the overall required resources remain a heavy burden on edge devices. Instead, Retrieval-Augmented Generation (RAG), a resource-efficient LLM learning method, can improve the quality of the LLM-generated content without updating model parameters. However, the RAG-based LLM may involve repetitive searches on the profile data in every user-LLM interaction. This search can lead to significant latency along with the accumulation of user data. Conventional efforts to decrease latency result in restricting the size of saved user data, thus reducing the scalability of RAG as user data continuously grows. It remains an open question: how to free RAG from the constraints of latency and scalability on edge devices? In this paper, we propose a novel framework to accelerate RAG via Computing-in-Memory (CiM) architectures. It accelerates matrix multiplications by performing in-situ computation inside the memory while avoiding the expensive data transfer between the computing unit and memory. Our framework, Robust CiM-backed RAG (RoCR), utilizing a novel contrastive learning-based training method and noise-aware training, can enable RAG to efficiently search profile data with CiM. To the best of our knowledge, this is the first work utilizing CiM to accelerate RAG.
5/9/2024
💬
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Yujuan Ding, Wenqi Fan, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
0
0
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) techniques can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-generated content (AIGC), the powerful capacity of retrieval in RAG in providing additional knowledge enables retrieval-augmented generation to assist existing generative AI in producing high-quality outputs. Recently, large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, retrieval-augmented large language models have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in retrieval-augmented large language models (RA-LLMs), covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we categorize mainstream relevant work by application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research.
5/13/2024
Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers
Kunal Sawarkar, Abhilasha Mangal, Shivam Raj Solanki
0
0
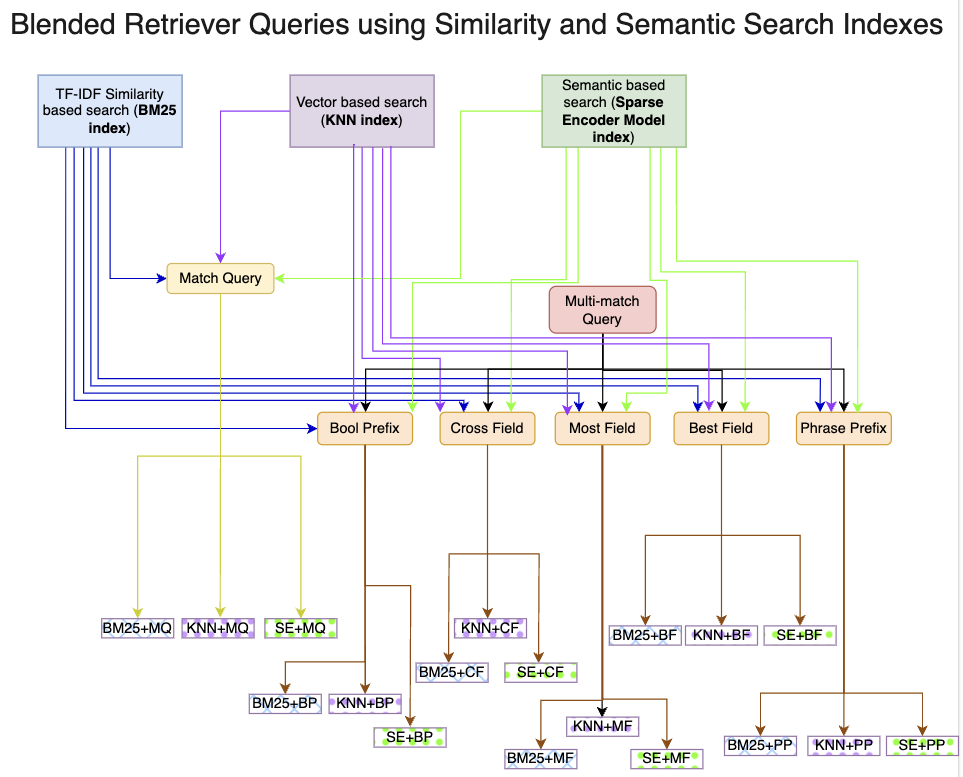
Retrieval-Augmented Generation (RAG) is a prevalent approach to infuse a private knowledge base of documents with Large Language Models (LLM) to build Generative Q&A (Question-Answering) systems. However, RAG accuracy becomes increasingly challenging as the corpus of documents scales up, with Retrievers playing an outsized role in the overall RAG accuracy by extracting the most relevant document from the corpus to provide context to the LLM. In this paper, we propose the 'Blended RAG' method of leveraging semantic search techniques, such as Dense Vector indexes and Sparse Encoder indexes, blended with hybrid query strategies. Our study achieves better retrieval results and sets new benchmarks for IR (Information Retrieval) datasets like NQ and TREC-COVID datasets. We further extend such a 'Blended Retriever' to the RAG system to demonstrate far superior results on Generative Q&A datasets like SQUAD, even surpassing fine-tuning performance.
4/12/2024