Nightshade: Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models
2310.13828
3
0
🤔
Abstract
Data poisoning attacks manipulate training data to introduce unexpected behaviors into machine learning models at training time. For text-to-image generative models with massive training datasets, current understanding of poisoning attacks suggests that a successful attack would require injecting millions of poison samples into their training pipeline. In this paper, we show that poisoning attacks can be successful on generative models. We observe that training data per concept can be quite limited in these models, making them vulnerable to prompt-specific poisoning attacks, which target a model's ability to respond to individual prompts. We introduce Nightshade, an optimized prompt-specific poisoning attack where poison samples look visually identical to benign images with matching text prompts. Nightshade poison samples are also optimized for potency and can corrupt an Stable Diffusion SDXL prompt in <100 poison samples. Nightshade poison effects bleed through to related concepts, and multiple attacks can composed together in a single prompt. Surprisingly, we show that a moderate number of Nightshade attacks can destabilize general features in a text-to-image generative model, effectively disabling its ability to generate meaningful images. Finally, we propose the use of Nightshade and similar tools as a last defense for content creators against web scrapers that ignore opt-out/do-not-crawl directives, and discuss possible implications for model trainers and content creators.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the vulnerability of text-to-image generative models to data poisoning attacks, where malicious samples are injected into the training data to manipulate the model's behavior.
- The authors introduce a specific type of attack called "Nightshade," which can corrupt a model's response to individual prompts with a relatively small number of poison samples.
- The paper also discusses potential implications for content creators and model trainers, as well as the use of Nightshade as a defense against web scrapers that ignore opt-out/do-not-crawl directives.
Plain English Explanation
Machine learning models, like those used for text-to-image generation, are trained on large datasets. Data poisoning attacks try to sneak in malicious samples into these training datasets, which can then cause the model to behave in unexpected ways.
The researchers found that text-to-image models, like Stable Diffusion, are particularly vulnerable to a specific type of attack called "Nightshade." In this attack, the researchers create poison samples that look very similar to normal images, but have subtle differences in the text prompts. When the model is trained on these poison samples, it becomes confused and starts generating incorrect or distorted images in response to certain prompts.
Surprisingly, the researchers found that even a moderate number of Nightshade attacks can significantly degrade the overall performance of the text-to-image model, making it unable to generate meaningful images. This could be a problem for content creators, who may want to protect their work from being copied by web scrapers that ignore opt-out/do-not-crawl directives.
The researchers also suggest that this type of attack could be a concern for the developers of text-to-image models, as it highlights the importance of robust training data and defense mechanisms against prompt-stealing attacks.
Technical Explanation
The paper explores the vulnerability of text-to-image generative models, such as Stable Diffusion, to data poisoning attacks. The authors observe that these models typically have a large training dataset, but the number of samples per individual concept can be quite limited. This makes them susceptible to prompt-specific poisoning attacks, where the goal is to corrupt the model's ability to respond to specific prompts.
The authors introduce "Nightshade," an optimized prompt-specific poisoning attack. Nightshade poison samples are visually identical to benign images but have subtle differences in the accompanying text prompts. These poison samples are also optimized for potency, meaning that a relatively small number (less than 100) can corrupt a Stable Diffusion SDXL prompt.
The paper shows that the effects of Nightshade attacks can "bleed through" to related concepts, and multiple attacks can be composed together in a single prompt. Surprisingly, the researchers found that a moderate number of Nightshade attacks can destabilize the general features of a text-to-image generative model, effectively disabling its ability to generate meaningful images.
The authors also propose the use of Nightshade and similar tools as a last defense for content creators against web scrapers that ignore opt-out/do-not-crawl directives. They discuss the potential implications for model trainers and content creators, highlighting the importance of robust training data and defense mechanisms against prompt-stealing attacks.
Critical Analysis
The paper provides a comprehensive and technically detailed exploration of prompt-specific poisoning attacks on text-to-image generative models. However, it is important to note that the research is focused on a specific type of attack (Nightshade) and may not cover the full scope of potential data poisoning vulnerabilities in these models.
The authors acknowledge that their research is limited to a single text-to-image model (Stable Diffusion) and that further research is needed to understand the broader applicability of their findings. Additionally, the paper does not address potential defenses or countermeasures against these types of attacks, which would be an important area for future work.
While the use of Nightshade as a defense against web scrapers is an interesting idea, it raises ethical concerns about the potential for misuse and the potential impact on the larger AI ecosystem. [Researchers have raised similar concerns about the development of tools for manipulating recommender systems or toxicity prediction models, which could be used for malicious purposes.
Overall, the paper makes a valuable contribution to the understanding of data poisoning attacks on text-to-image generative models, but more research is needed to explore the broader implications and potential countermeasures.
Conclusion
This paper highlights the vulnerability of text-to-image generative models, such as Stable Diffusion, to data poisoning attacks. The authors introduce a specific type of attack called "Nightshade," which can corrupt a model's response to individual prompts with a relatively small number of poison samples.
The paper's findings suggest that even a moderate number of Nightshade attacks can significantly degrade the overall performance of a text-to-image model, making it unable to generate meaningful images. This has implications for content creators, who may want to protect their work from being copied by web scrapers, as well as for the developers of these models, who need to ensure robust training data and defense mechanisms against prompt-stealing attacks.
While the use of Nightshade as a defense against web scrapers is an interesting idea, it also raises ethical concerns about the potential for misuse. Further research is needed to explore the broader implications of data poisoning attacks and develop effective countermeasures to maintain the integrity and reliability of text-to-image generative models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Prompt Stealing Attacks Against Text-to-Image Generation Models
Xinyue Shen, Yiting Qu, Michael Backes, Yang Zhang
0
0
Text-to-Image generation models have revolutionized the artwork design process and enabled anyone to create high-quality images by entering text descriptions called prompts. Creating a high-quality prompt that consists of a subject and several modifiers can be time-consuming and costly. In consequence, a trend of trading high-quality prompts on specialized marketplaces has emerged. In this paper, we perform the first study on understanding the threat of a novel attack, namely prompt stealing attack, which aims to steal prompts from generated images by text-to-image generation models. Successful prompt stealing attacks directly violate the intellectual property of prompt engineers and jeopardize the business model of prompt marketplaces. We first perform a systematic analysis on a dataset collected by ourselves and show that a successful prompt stealing attack should consider a prompt's subject as well as its modifiers. Based on this observation, we propose a simple yet effective prompt stealing attack, PromptStealer. It consists of two modules: a subject generator trained to infer the subject and a modifier detector for identifying the modifiers within the generated image. Experimental results demonstrate that PromptStealer is superior over three baseline methods, both quantitatively and qualitatively. We also make some initial attempts to defend PromptStealer. In general, our study uncovers a new attack vector within the ecosystem established by the popular text-to-image generation models. We hope our results can contribute to understanding and mitigating this emerging threat.
4/16/2024
🏋️
Poisoning Web-Scale Training Datasets is Practical
Nicholas Carlini, Matthew Jagielski, Christopher A. Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, Florian Tram`er
0
0
Deep learning models are often trained on distributed, web-scale datasets crawled from the internet. In this paper, we introduce two new dataset poisoning attacks that intentionally introduce malicious examples to a model's performance. Our attacks are immediately practical and could, today, poison 10 popular datasets. Our first attack, split-view poisoning, exploits the mutable nature of internet content to ensure a dataset annotator's initial view of the dataset differs from the view downloaded by subsequent clients. By exploiting specific invalid trust assumptions, we show how we could have poisoned 0.01% of the LAION-400M or COYO-700M datasets for just $60 USD. Our second attack, frontrunning poisoning, targets web-scale datasets that periodically snapshot crowd-sourced content -- such as Wikipedia -- where an attacker only needs a time-limited window to inject malicious examples. In light of both attacks, we notify the maintainers of each affected dataset and recommended several low-overhead defenses.
5/7/2024
Poisoning-based Backdoor Attacks for Arbitrary Target Label with Positive Triggers
Binxiao Huang, Jason Chun Lok, Chang Liu, Ngai Wong
0
0
Poisoning-based backdoor attacks expose vulnerabilities in the data preparation stage of deep neural network (DNN) training. The DNNs trained on the poisoned dataset will be embedded with a backdoor, making them behave well on clean data while outputting malicious predictions whenever a trigger is applied. To exploit the abundant information contained in the input data to output label mapping, our scheme utilizes the network trained from the clean dataset as a trigger generator to produce poisons that significantly raise the success rate of backdoor attacks versus conventional approaches. Specifically, we provide a new categorization of triggers inspired by the adversarial technique and develop a multi-label and multi-payload Poisoning-based backdoor attack with Positive Triggers (PPT), which effectively moves the input closer to the target label on benign classifiers. After the classifier is trained on the poisoned dataset, we can generate an input-label-aware trigger to make the infected classifier predict any given input to any target label with a high possibility. Under both dirty- and clean-label settings, we show empirically that the proposed attack achieves a high attack success rate without sacrificing accuracy across various datasets, including SVHN, CIFAR10, GTSRB, and Tiny ImageNet. Furthermore, the PPT attack can elude a variety of classical backdoor defenses, proving its effectiveness.
5/10/2024
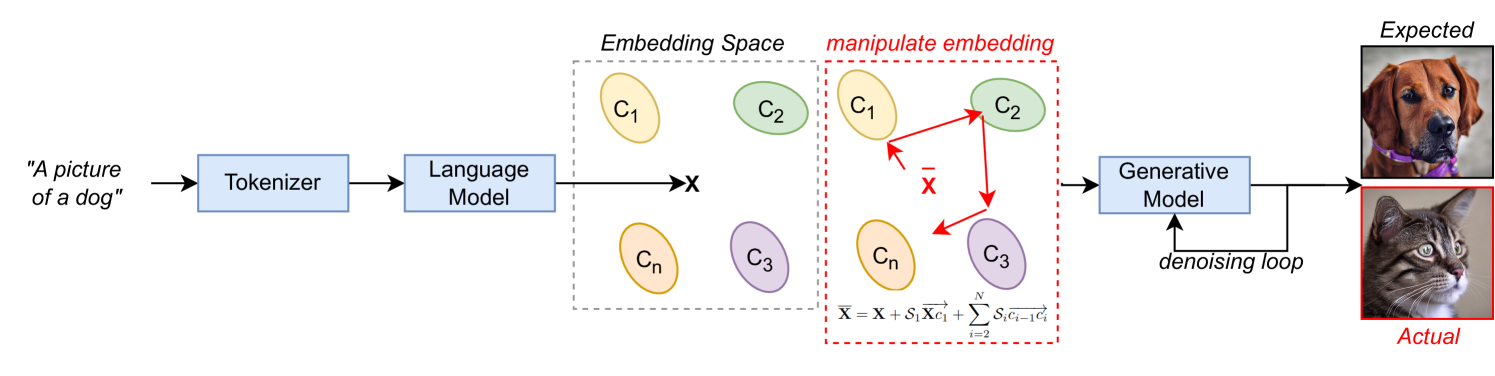
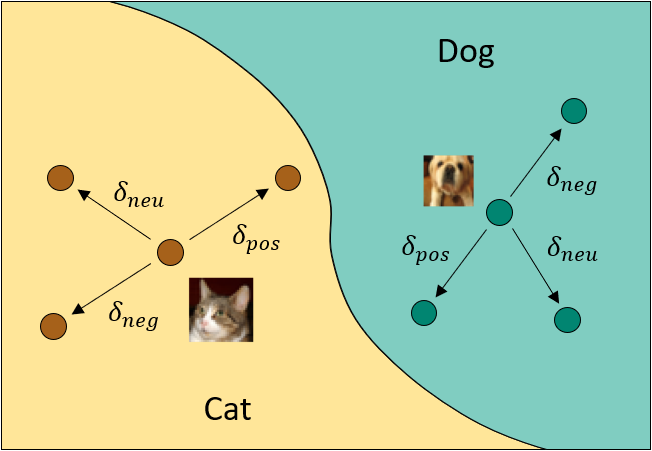
Severity Controlled Text-to-Image Generative Model Bias Manipulation
Jordan Vice, Naveed Akhtar, Richard Hartley, Ajmal Mian
0
0
Text-to-image (T2I) generative models are gaining wide popularity, especially in public domains. However, their intrinsic bias and potential malicious manipulations remain under-explored. Charting the susceptibility of T2I models to such manipulation, we first expose the new possibility of a dynamic and computationally efficient exploitation of model bias by targeting the embedded language models. By leveraging mathematical foundations of vector algebra, our technique enables a scalable and convenient control over the severity of output manipulation through model bias. As a by-product, this control also allows a form of precise prompt engineering to generate images which are generally implausible with regular text prompts. We also demonstrate a constructive application of our manipulation for balancing the frequency of generated classes - as in model debiasing. Our technique does not require training and is also framed as a backdoor attack with severity control using semantically-null text triggers in the prompts. With extensive analysis, we present interesting qualitative and quantitative results to expose potential manipulation possibilities for T2I models. Key-words: Text-to-Image Models, Generative Models, Backdoor Attacks, Prompt Engineering, Bias
4/4/2024