Iterative Reasoning Preference Optimization
2404.19733
19
9
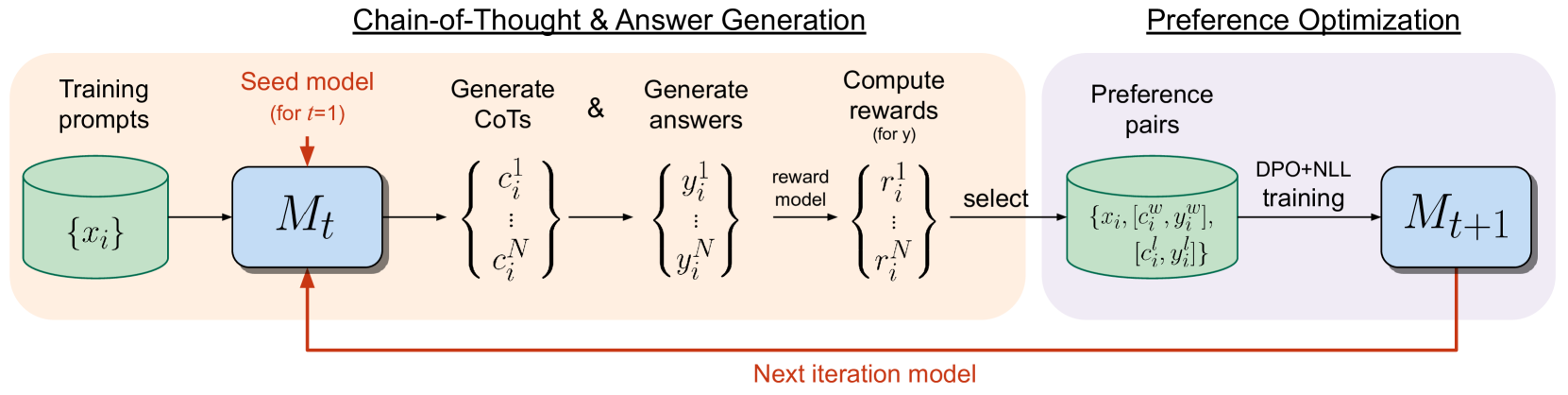
Abstract
Iterative preference optimization methods have recently been shown to perform well for general instruction tuning tasks, but typically make little improvement on reasoning tasks (Yuan et al., 2024, Chen et al., 2024). In this work we develop an iterative approach that optimizes the preference between competing generated Chain-of-Thought (CoT) candidates by optimizing for winning vs. losing reasoning steps that lead to the correct answer. We train using a modified DPO loss (Rafailov et al., 2023) with an additional negative log-likelihood term, which we find to be crucial. We show reasoning improves across repeated iterations of this scheme. While only relying on examples in the training set, our approach results in increasing accuracy on GSM8K, MATH, and ARC-Challenge for Llama-2-70B-Chat, outperforming other Llama-2-based models not relying on additionally sourced datasets. For example, we see a large improvement from 55.6% to 81.6% on GSM8K and an accuracy of 88.7% with majority voting out of 32 samples.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a novel approach called "Iterative Reasoning Preference Optimization" (IRPO) for optimizing preferences in multi-agent systems through iterative reasoning.
- The key idea is to model the reasoning process of agents as they interact and adjust their preferences over time, leading to a stable convergence of preferences.
- The authors demonstrate the effectiveness of IRPO through experiments in various decision-making scenarios, including resource allocation and negotiation.
Plain English Explanation
The paper presents a new way to optimize preferences in systems with multiple decision-makers or "agents." The core concept is to model how these agents reason and adjust their preferences over time as they interact with each other. This iterative reasoning process eventually leads to a stable set of preferences that all the agents can agree on.
For example, imagine a group of people trying to decide how to allocate a limited budget. Each person has their own priorities and preferences for how the money should be spent. Using the IRPO approach, the group would engage in a back-and-forth discussion, with each person adjusting their preferences based on the arguments and compromises made by the others. Over time, the group would converge on a set of preferences that everyone can accept, even if it's not exactly what any one person wanted initially.
The authors show that this iterative reasoning approach works well in various decision-making scenarios, such as allocating resources or negotiating between parties with different interests. By modeling how preferences evolve through discussion and compromise, the IRPO method can help find solutions that satisfy all stakeholders.
Technical Explanation
The paper introduces the "Iterative Reasoning Preference Optimization" (IRPO) framework, which models the iterative process of preference adjustment among a group of agents in a multi-agent system. The key idea is to capture the dynamic nature of preferences as agents engage in reasoning and negotiation.
The IRPO approach works as follows:
- Each agent has an initial set of preferences, represented as a utility function.
- Agents take turns updating their preferences based on the preferences of the other agents, using a reasoning process that aims to maximize their own utility while considering the tradeoffs.
- This iterative process continues until the preferences converge to a stable equilibrium, where no agent has an incentive to further adjust their preferences.
The authors demonstrate the IRPO approach in several decision-making scenarios, such as resource allocation and negotiation. They show that the iterative reasoning process leads to outcomes that satisfy all agents, even when their initial preferences are in conflict.
Critical Analysis
The paper presents a promising approach to optimizing preferences in multi-agent systems, but it also acknowledges several limitations and areas for future research:
- The convergence properties of the IRPO framework are not fully characterized, and the authors note that the process may not always converge to a stable equilibrium, especially in complex scenarios with many agents and preferences.
- The computational complexity of the iterative reasoning process may be a challenge, particularly in large-scale systems with many agents and preferences. The authors suggest exploring more efficient reasoning algorithms to address this issue.
- The paper does not explore the impact of strategic behavior by agents, where they may try to manipulate the process to their advantage. Extending the IRPO framework to account for such strategic considerations could be an area for future research.
Overall, the IRPO approach is a valuable contribution to the field of multi-agent systems and preference optimization. The authors demonstrate the potential of modeling the iterative reasoning process to achieve stable and mutually satisfactory outcomes. However, further research is needed to address the limitations and explore the broader applicability of the approach.
Conclusion
The "Iterative Reasoning Preference Optimization" (IRPO) framework proposed in this paper offers a novel way to optimize preferences in multi-agent systems. By modeling the iterative reasoning process through which agents adjust their preferences, the IRPO method can lead to stable and mutually satisfactory outcomes, even in complex decision-making scenarios with competing interests.
The key strength of IRPO is its ability to capture the dynamic nature of preferences and the role of negotiation and compromise in reaching consensus. This approach has important implications for a wide range of applications, from resource allocation to policy-making.
While the paper highlights some limitations and areas for future research, the IRPO framework represents a significant advancement in the field of multi-agent systems and preference optimization. As the authors demonstrate, modeling the iterative reasoning process can be a powerful tool for navigating the complexities of collective decision-making and achieving outcomes that satisfy all stakeholders.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, Michael Shieh
0
0
We introduce an approach aimed at enhancing the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful strategy employed by AlphaZero. Our work leverages Monte Carlo Tree Search (MCTS) to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals. To enhance consistency in intermediate steps, we combine outcome validation and stepwise self-evaluation, continually updating the quality assessment of newly generated data. The proposed algorithm employs Direct Preference Optimization (DPO) to update the LLM policy using this newly generated step-level preference data. Theoretical analysis reveals the critical importance of using on-policy sampled data for successful self-improving. Extensive evaluations on various arithmetic and commonsense reasoning tasks demonstrate remarkable performance improvements over existing models. For instance, our approach outperforms the Mistral-7B Supervised Fine-Tuning (SFT) baseline on GSM8K, MATH, and SciQ, with substantial percentage increases in accuracy to $80.7%$ (+$4.8%$), $32.2%$ (+$3.3%$), and $88.5%$ (+$7.7%$), respectively. Additionally, our research delves into the training and inference compute tradeoff, providing insights into how our method effectively maximizes performance gains.
5/2/2024
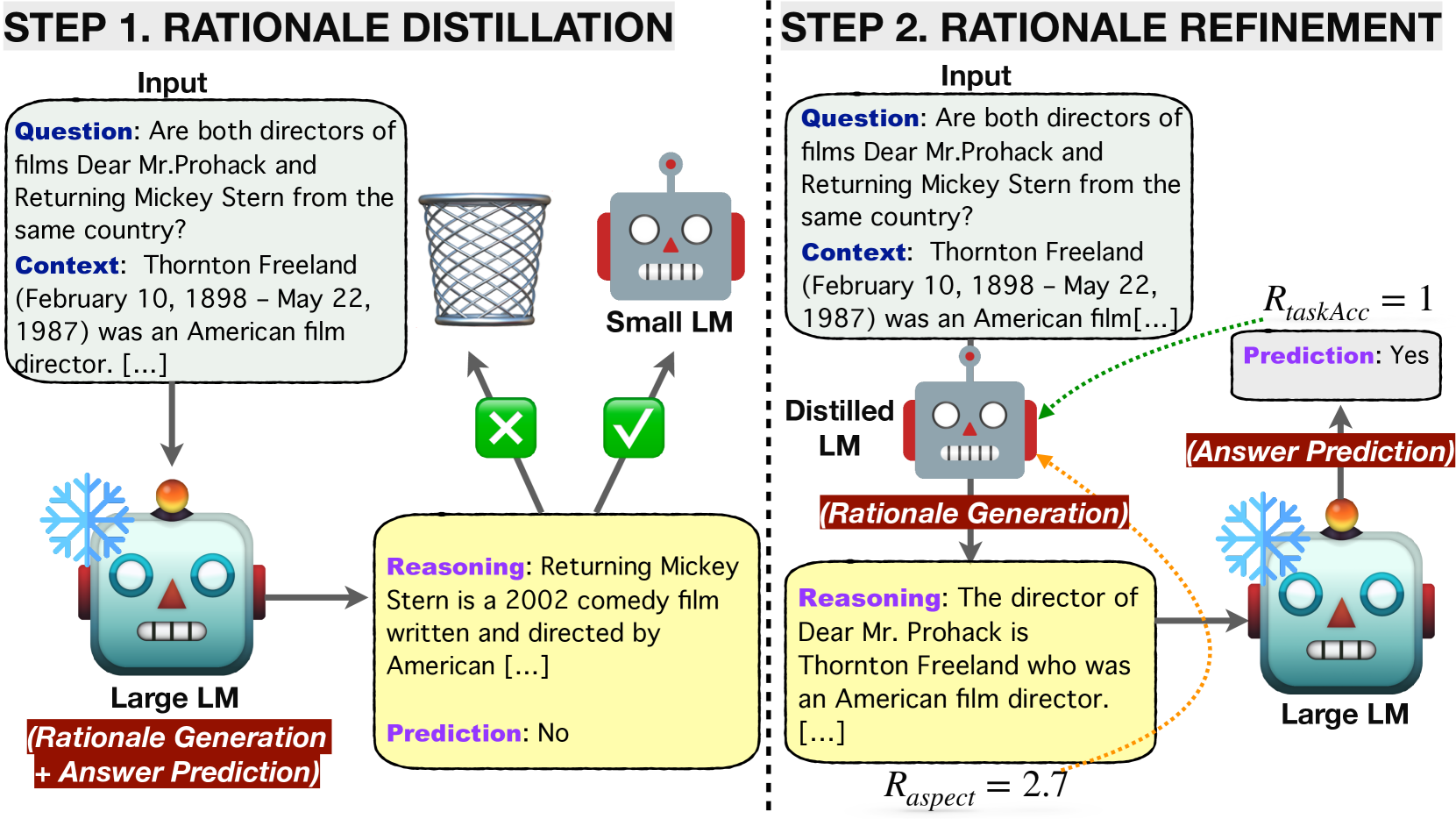
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
0
0
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
4/5/2024
✅
Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing
Fangkai Jiao, Chengwei Qin, Zhengyuan Liu, Nancy F. Chen, Shafiq Joty
0
0
Large Language Models (LLMs) have demonstrated significant potential in handling complex reasoning tasks through step-by-step rationale generation. However, recent studies have raised concerns regarding the hallucination and flaws in their reasoning process. Substantial efforts are being made to improve the reliability and faithfulness of the generated rationales. Some approaches model reasoning as planning, while others focus on annotating for process supervision. Nevertheless, the planning-based search process often results in high latency due to the frequent assessment of intermediate reasoning states and the extensive exploration space. Additionally, supervising the reasoning process with human annotation is costly and challenging to scale for LLM training. To address these issues, in this paper, we propose a framework to learn planning-based reasoning through Direct Preference Optimization (DPO) on collected trajectories, which are ranked according to synthesized process rewards. Our results on challenging logical reasoning benchmarks demonstrate the effectiveness of our learning framework, showing that our 7B model can surpass the strong counterparts like GPT-3.5-Turbo.
4/16/2024

CoTAR: Chain-of-Thought Attribution Reasoning with Multi-level Granularity
Moshe Berchansky, Daniel Fleischer, Moshe Wasserblat, Peter Izsak
0
0
State-of-the-art performance in QA tasks is currently achieved by systems employing Large Language Models (LLMs), however these models tend to hallucinate information in their responses. One approach focuses on enhancing the generation process by incorporating attribution from the given input to the output. However, the challenge of identifying appropriate attributions and verifying their accuracy against a source is a complex task that requires significant improvements in assessing such systems. We introduce an attribution-oriented Chain-of-Thought reasoning method to enhance the accuracy of attributions. This approach focuses the reasoning process on generating an attribution-centric output. Evaluations on two context-enhanced question-answering datasets using GPT-4 demonstrate improved accuracy and correctness of attributions. In addition, the combination of our method with finetuning enhances the response and attribution accuracy of two smaller LLMs, showing their potential to outperform GPT-4 in some cases.
4/17/2024