InstructEdit: Instruction-based Knowledge Editing for Large Language Models
2402.16123
0
11
💬
Abstract
Knowledge editing for large language models can offer an efficient solution to alter a model's behavior without negatively impacting the overall performance. However, the current approaches encounter issues with limited generalizability across tasks, necessitating one distinct editor for each task, significantly hindering the broader applications. To address this, we take the first step to analyze the multi-task generalization issue in knowledge editing. Specifically, we develop an instruction-based editing technique, termed InstructEdit, which facilitates the editor's adaptation to various task performances simultaneously using simple instructions. With only one unified editor for each LLM, we empirically demonstrate that InstructEdit can improve the editor's control, leading to an average 14.86% increase in Reliability in multi-task editing setting. Furthermore, experiments involving holdout unseen task illustrate that InstructEdit consistently surpass previous strong baselines. To further investigate the underlying mechanisms of instruction-based knowledge editing, we analyze the principal components of the editing gradient directions, which unveils that instructions can help control optimization direction with stronger OOD generalization. Code and datasets are available in https://github.com/zjunlp/EasyEdit.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers propose a new technique called InstructEdit to improve knowledge editing for large language models (LLMs)
- Current approaches have limited generalizability across tasks, requiring a distinct editor for each task
- InstructEdit aims to enable a single unified editor to improve performance on multiple tasks simultaneously using simple instructions
- Experiments show InstructEdit can improve reliability by 14.86% on average in a multi-task setting and outperform previous baselines on unseen tasks
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, their behavior can be unpredictable or undesirable in certain situations. Knowledge editing for large language models can offer an efficient solution to alter a model's behavior without negatively impacting the overall performance.
The current approaches to knowledge editing have a significant limitation - they are often tailored to a specific task, meaning a new editor needs to be developed for each different task. This makes it difficult to apply knowledge editing more broadly. To address this issue, the researchers developed a new technique called InstructEdit.
InstructEdit allows a single unified editor to be used across multiple tasks. Instead of creating a separate editor for each task, InstructEdit uses simple instructions to guide the editor's behavior. This means the same editor can be used to improve the model's performance on a variety of different tasks, making knowledge editing much more efficient and flexible.
The researchers found that InstructEdit was able to improve the model's "reliability" - its consistency and trustworthiness - by an average of 14.86% in a multi-task setting. Additionally, when tested on completely new, unseen tasks, InstructEdit outperformed previous state-of-the-art approaches.
Overall, this research is a significant step forward in making knowledge editing more practical and widely applicable for improving the behavior of large language models.
Technical Explanation
The key idea behind InstructEdit is to develop an instruction-based editing technique that can adapt to various task performances simultaneously using simple instructions. This addresses the limitation of current approaches, which require a distinct editor for each task, significantly hindering broader applications.
The researchers empirically demonstrate that InstructEdit can improve the editor's control, leading to an average 14.86% increase in Reliability in a multi-task editing setting. Furthermore, experiments involving holdout unseen tasks illustrate that InstructEdit consistently outperforms previous strong baselines.
To understand the underlying mechanisms of instruction-based knowledge editing, the researchers analyze the principal components of the editing gradient directions. This analysis reveals that instructions can help control the optimization direction, resulting in stronger out-of-distribution (OOD) generalization.
The researchers make their code and datasets available to facilitate further research in this area. This work represents a significant advancement in the field of knowledge editing for large language models, paving the way for more efficient and versatile methods to improve the behavior of these powerful AI systems.
Critical Analysis
The researchers have made a compelling case for the benefits of InstructEdit, demonstrating its ability to outperform previous approaches in multi-task and unseen task settings. However, the paper does not explore the limitations or potential drawbacks of this technique.
For example, the paper does not discuss the complexity or computational cost of the InstructEdit approach compared to other knowledge editing methods. Additionally, it's unclear how the performance of InstructEdit scales with the number of tasks or the complexity of the instructions provided.
Furthermore, the paper does not address potential ethical concerns around the use of knowledge editing, such as the risk of unintended biases or the potential for misuse. As large language models become more capable and widely deployed, it is crucial to consider the broader implications of techniques like InstructEdit.
Future research in this area should explore these limitations and potential issues more thoroughly, ensuring that knowledge editing techniques are developed and applied in a responsible and ethical manner. Additionally, evaluating InstructEdit on a broader range of tasks and datasets, including real-world applications, would further validate the effectiveness and generalizability of this approach.
Conclusion
The research presented in this paper represents a significant advancement in the field of knowledge editing for large language models. The InstructEdit technique offers a more efficient and flexible solution compared to previous approaches, allowing a single unified editor to be used across multiple tasks.
The empirical results demonstrate the effectiveness of InstructEdit, with an average 14.86% increase in Reliability in a multi-task setting and consistent outperformance on unseen tasks. This suggests that InstructEdit can help improve the reliability and trustworthiness of large language models, which is crucial as these powerful AI systems become more widely deployed.
While the paper does not address all the potential limitations and concerns, this research represents an important step forward in the ongoing efforts to enhance the behavior and capabilities of large language models. As the field continues to evolve, it will be essential to build on these advancements while also prioritizing the ethical and responsible development of knowledge editing techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Detecting Edited Knowledge in Language Models
Paul Youssef, Zhixue Zhao, Jorg Schlotterer, Christin Seifert
0
0
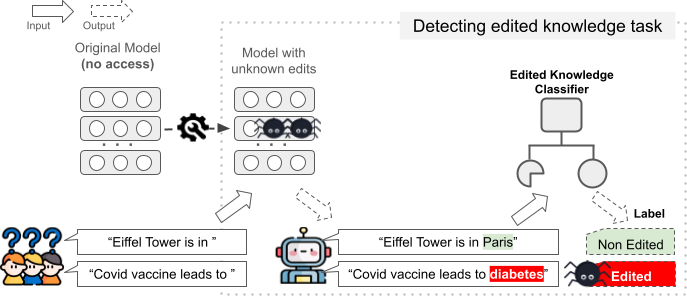
Knowledge editing techniques (KEs) can update language models' obsolete or inaccurate knowledge learned from pre-training. However, KE also faces potential malicious applications, e.g. inserting misinformation and toxic content. Moreover, in the context of responsible AI, it is instructive for end-users to know whether a generated output is driven by edited knowledge or first-hand knowledge from pre-training. To this end, we study detecting edited knowledge in language models by introducing a novel task: given an edited model and a specific piece of knowledge the model generates, our objective is to classify the knowledge as either non-edited (based on the pre-training), or ``edited'' (based on subsequent editing). We initiate the task with two state-of-the-art KEs, two language models, and two datasets. We further propose a simple classifier, RepReg, a logistic regression model that takes hidden state representations as input features. Our results reveal that RepReg establishes a strong baseline, achieving a peak accuracy of 99.81%, and 97.79% in out-of-domain settings. Second, RepReg achieves near-optimal performance with a limited training set (200 training samples), and it maintains its performance even in out-of-domain settings. Last, we find it more challenging to separate edited and non-edited knowledge when they contain the same subject or object.
5/7/2024
New!Unveiling the Pitfalls of Knowledge Editing for Large Language Models
Zhoubo Li, Ningyu Zhang, Yunzhi Yao, Mengru Wang, Xi Chen, Huajun Chen
0
0
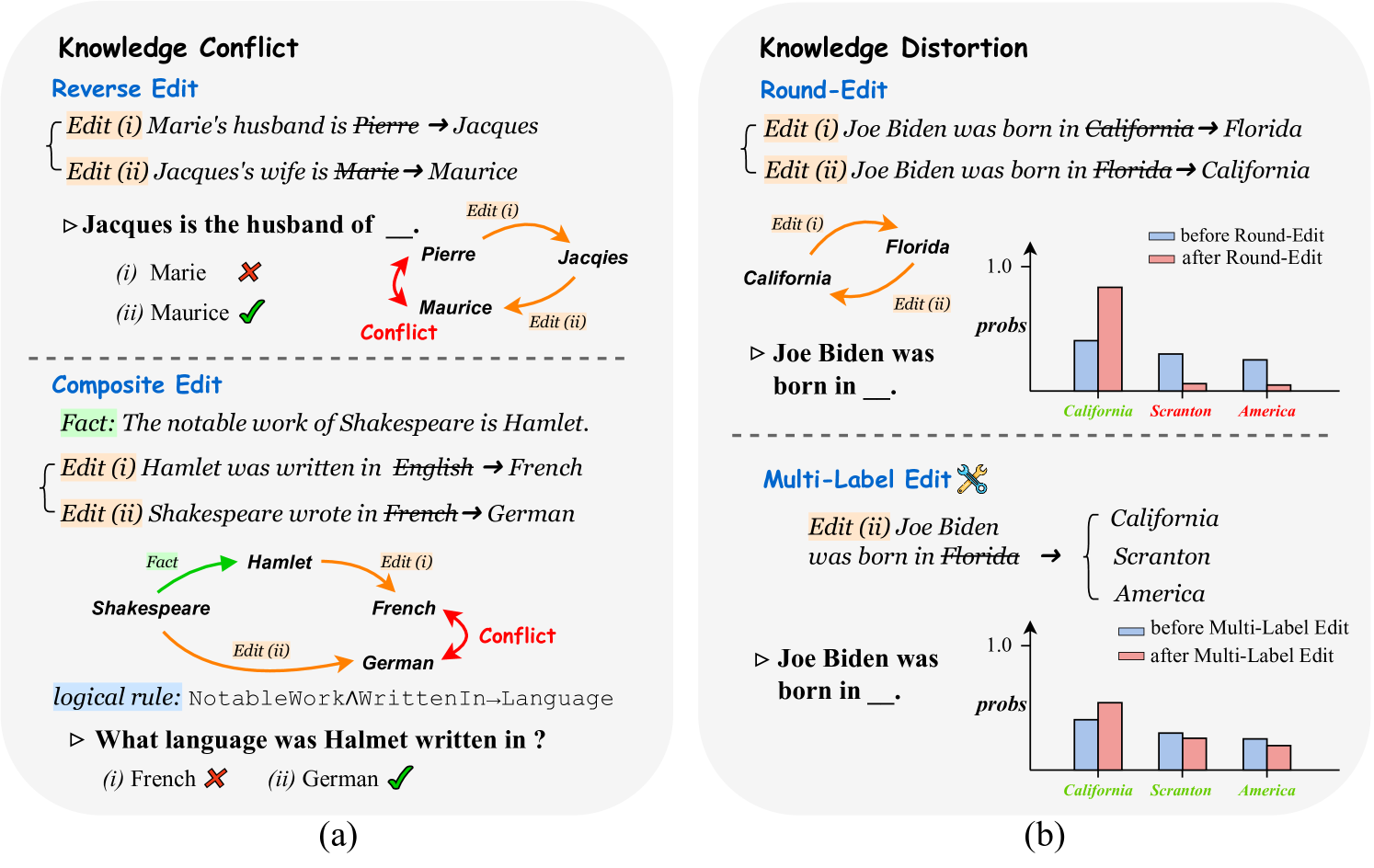
As the cost associated with fine-tuning Large Language Models (LLMs) continues to rise, recent research efforts have pivoted towards developing methodologies to edit implicit knowledge embedded within LLMs. Yet, there's still a dark cloud lingering overhead -- will knowledge editing trigger butterfly effect? since it is still unclear whether knowledge editing might introduce side effects that pose potential risks or not. This paper pioneers the investigation into the potential pitfalls associated with knowledge editing for LLMs. To achieve this, we introduce new benchmark datasets and propose innovative evaluation metrics. Our results underline two pivotal concerns: (1) Knowledge Conflict: Editing groups of facts that logically clash can magnify the inherent inconsistencies in LLMs-a facet neglected by previous methods. (2) Knowledge Distortion: Altering parameters with the aim of editing factual knowledge can irrevocably warp the innate knowledge structure of LLMs. Experimental results vividly demonstrate that knowledge editing might inadvertently cast a shadow of unintended consequences on LLMs, which warrant attention and efforts for future works. Code and data are available at https://github.com/zjunlp/PitfallsKnowledgeEditing.
5/14/2024

Event-level Knowledge Editing
Hao Peng, Xiaozhi Wang, Chunyang Li, Kaisheng Zeng, Jiangshan Duo, Yixin Cao, Lei Hou, Juanzi Li
0
0
Knowledge editing aims at updating knowledge of large language models (LLMs) to prevent them from becoming outdated. Existing work edits LLMs at the level of factual knowledge triplets. However, natural knowledge updates in the real world come from the occurrences of new events rather than direct changes in factual triplets. In this paper, we propose a new task setting: event-level knowledge editing, which directly edits new events into LLMs and improves over conventional triplet-level editing on (1) Efficiency. A single event edit leads to updates in multiple entailed knowledge triplets. (2) Completeness. Beyond updating factual knowledge, event-level editing also requires considering the event influences and updating LLMs' knowledge about future trends. We construct a high-quality event-level editing benchmark ELKEN, consisting of 1,515 event edits, 6,449 questions about factual knowledge, and 10,150 questions about future tendencies. We systematically evaluate the performance of various knowledge editing methods and LLMs on this benchmark. We find that ELKEN poses significant challenges to existing knowledge editing approaches. Our codes and dataset are publicly released to facilitate further research.
4/23/2024
⛏️
InstructIE: A Bilingual Instruction-based Information Extraction Dataset
Honghao Gui, Shuofei Qiao, Jintian Zhang, Hongbin Ye, Mengshu Sun, Lei Liang, Jeff Z. Pan, Huajun Chen, Ningyu Zhang
0
0
Large language models can perform well on general natural language tasks, but their effectiveness is still not optimal for information extraction. Recent works indicate that the main reason lies in the lack of extensive data on information extraction instructions. Note that the existing datasets on information extraction instructions not only have limited coverage but also involve high construction costs. To address this issue, we introduce InstructIE, a bilingual instruction-based information extraction dataset, which covers 12 diverse domains. Specifically, we propose KG2Instruction, a framework specifically for the automatic generation of such datasets. Experimental results demonstrate that large language models trained with InstructIE can not only obtain better information extraction capabilities but also enhance zero-shot performance compared with baselines.
4/19/2024