Extending Llama-3's Context Ten-Fold Overnight
2404.19553
2
173
⛏️
Abstract
We extend the context length of Llama-3-8B-Instruct from 8K to 80K via QLoRA fine-tuning. The entire training cycle is super efficient, which takes 8 hours on one 8xA800 (80G) GPU machine. The resulted model exhibits superior performances across a broad range of evaluation tasks, such as NIHS, topic retrieval, and long-context language understanding; meanwhile, it also well preserves the original capability over short contexts. The dramatic context extension is mainly attributed to merely 3.5K synthetic training samples generated by GPT-4 , which indicates the LLMs' inherent (yet largely underestimated) potential to extend its original context length. In fact, the context length could be extended far beyond 80K with more computation resources. Therefore, the team will publicly release the entire resources (including data, model, data generation pipeline, training code) so as to facilitate the future research from the community: url{https://github.com/FlagOpen/FlagEmbedding}.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Extends the context length of Llama-3-8B-Instruct model from 8K to 80K via QLoRA fine-tuning
- Training takes only 8 hours on a single 8xA800 (80G) GPU machine
- Resulted model exhibits superior performance on a range of evaluation tasks, including long-context language understanding
- Preserves original capability over short contexts
- Dramatic context extension achieved with just 3.5K synthetic training samples generated by GPT-4
- Highlights the potential for large language models (LLMs) to extend their original context length with more computational resources
Plain English Explanation
The researchers extended the context length of a large language model called Llama-3-8B-Instruct from 8,000 tokens to 80,000 tokens. This means the model can now process and understand much longer pieces of text.
They did this by fine-tuning the model using a technique called Quantized Low-Rank Adaptation (QLoRA), which is an efficient way to update the model's parameters. The entire training process only took 8 hours on a single powerful GPU.
The resulting model performed very well on a variety of tasks that require understanding long passages of text, such as answering questions about a topic or summarizing the key points. Importantly, it also maintained its original ability to process short pieces of text effectively.
The researchers found that they could achieve this dramatic increase in context length by using just 3,500 synthetic training samples generated by an even more powerful language model, GPT-4. This suggests that large language models have a lot of untapped potential to handle longer contexts, and that with more computing power, their context length could be extended even further.
Technical Explanation
The researchers extended the context length of the Llama-3-8B-Instruct model from 8,000 tokens to 80,000 tokens using Quantized Low-Rank Adaptation (QLoRA) fine-tuning. This efficient training process took only 8 hours on a single 8xA800 (80G) GPU machine.
The resulting model demonstrated superior performance across a range of evaluation tasks, including natural language inference, topic retrieval, and long-context language understanding. Importantly, the model also well preserved its original capability over short contexts.
The researchers attribute the dramatic context extension to the use of just 3,500 synthetic training samples generated by the powerful GPT-4 model. This indicates that large language models have significant untapped potential to extend their original context length with additional computational resources.
To facilitate future research, the team plans to publicly release the entire set of resources, including the data, model, data generation pipeline, and training code, through a GitHub repository.
Critical Analysis
The researchers provide a compelling demonstration of the potential for large language models to handle significantly longer contexts than their original capabilities. By leveraging efficient fine-tuning techniques and a relatively small amount of synthetic data, they were able to extend the context length of the Llama-3-8B-Instruct model by an order of magnitude.
However, the paper does not explore the limits of this context extension or the potential challenges that may arise as context lengths continue to grow. It would be valuable to understand the computational and memory requirements, as well as any potential trade-offs in model performance, as the context length is scaled even further.
Additionally, the researchers' claim that LLMs have "largely underestimated" potential to extend their context length could benefit from a more nuanced discussion. While the results are impressive, it is important to consider the potential challenges and limitations that may arise as models are pushed to their boundaries.
Overall, this research represents an important step in advancing the capabilities of large language models and highlights the need for continued exploration and critical analysis in this rapidly evolving field.
Conclusion
The researchers have demonstrated a highly efficient method for extending the context length of the Llama-3-8B-Instruct model from 8,000 tokens to 80,000 tokens. This was achieved through QLoRA fine-tuning, which allowed the training process to be completed in just 8 hours on a single powerful GPU.
The resulting model exhibited superior performance on a range of evaluation tasks that require understanding long passages of text, while also preserving its original capability over short contexts. Importantly, the researchers were able to accomplish this dramatic context extension using a relatively small amount of synthetic training data, highlighting the inherent potential of large language models to handle longer contexts with additional computational resources.
By publicly releasing the entire set of resources, including the data, model, and training code, the researchers are poised to facilitate further research and advancements in the field of long-context language understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LongEmbed: Extending Embedding Models for Long Context Retrieval
Dawei Zhu, Liang Wang, Nan Yang, Yifan Song, Wenhao Wu, Furu Wei, Sujian Li
0
0
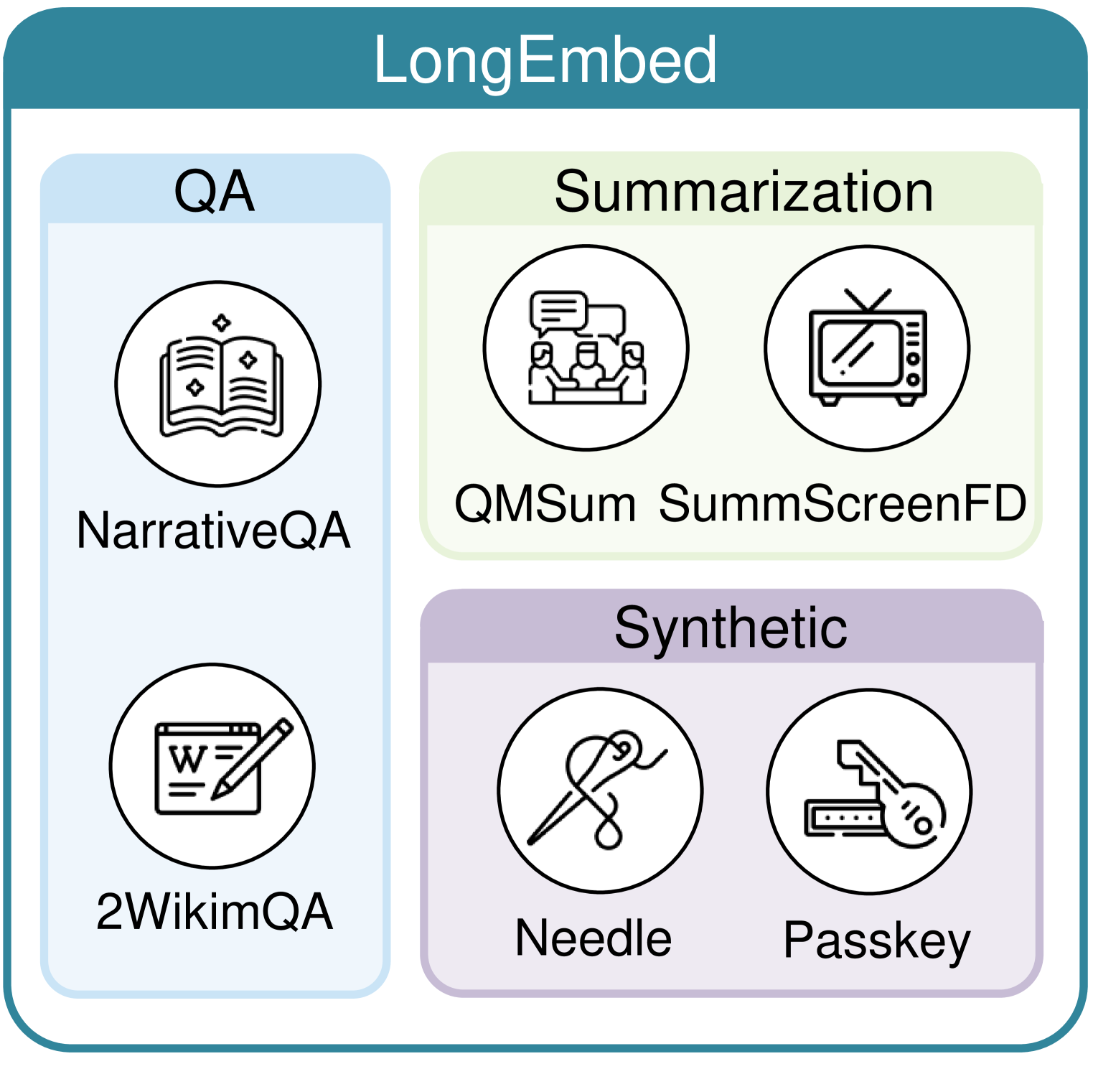
Embedding models play a pivot role in modern NLP applications such as IR and RAG. While the context limit of LLMs has been pushed beyond 1 million tokens, embedding models are still confined to a narrow context window not exceeding 8k tokens, refrained from application scenarios requiring long inputs such as legal contracts. This paper explores context window extension of existing embedding models, pushing the limit to 32k without requiring additional training. First, we examine the performance of current embedding models for long context retrieval on our newly constructed LongEmbed benchmark. LongEmbed comprises two synthetic tasks and four carefully chosen real-world tasks, featuring documents of varying length and dispersed target information. Benchmarking results underscore huge room for improvement in these models. Based on this, comprehensive experiments show that training-free context window extension strategies like position interpolation can effectively extend the context window of existing embedding models by several folds, regardless of their original context being 512 or beyond 4k. Furthermore, for models employing absolute position encoding (APE), we show the possibility of further fine-tuning to harvest notable performance gains while strictly preserving original behavior for short inputs. For models using rotary position embedding (RoPE), significant enhancements are observed when employing RoPE-specific methods, such as NTK and SelfExtend, indicating RoPE's superiority over APE for context window extension. To facilitate future research, we release E5-Base-4k and E5-RoPE-Base, along with the LongEmbed benchmark.
4/26/2024
LLoCO: Learning Long Contexts Offline
Sijun Tan, Xiuyu Li, Shishir Patil, Ziyang Wu, Tianjun Zhang, Kurt Keutzer, Joseph E. Gonzalez, Raluca Ada Popa
0
0
Processing long contexts remains a challenge for large language models (LLMs) due to the quadratic computational and memory overhead of the self-attention mechanism and the substantial KV cache sizes during generation. We propose a novel approach to address this problem by learning contexts offline through context compression and in-domain parameter-efficient finetuning. Our method enables an LLM to create a concise representation of the original context and efficiently retrieve relevant information to answer questions accurately. We introduce LLoCO, a technique that combines context compression, retrieval, and parameter-efficient finetuning using LoRA. Our approach extends the effective context window of a 4k token LLaMA2-7B model to handle up to 128k tokens. We evaluate our approach on several long-context question-answering datasets, demonstrating that LLoCO significantly outperforms in-context learning while using $30times$ fewer tokens during inference. LLoCO achieves up to $7.62times$ speed-up and substantially reduces the cost of long document question answering, making it a promising solution for efficient long context processing. Our code is publicly available at https://github.com/jeffreysijuntan/lloco.
4/12/2024

Long-context LLMs Struggle with Long In-context Learning
Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, Wenhu Chen
0
0
Large Language Models (LLMs) have made significant strides in handling long sequences exceeding 32K tokens. However, their performance evaluation has largely been confined to metrics like perplexity and synthetic tasks, which may not fully capture their abilities in more nuanced, real-world scenarios. This study introduces a specialized benchmark (LongICLBench) focusing on long in-context learning within the realm of extreme-label classification. We meticulously selected six datasets with a label range spanning 28 to 174 classes covering different input (few-shot demonstration) lengths from 2K to 50K tokens. Our benchmark requires LLMs to comprehend the entire input to recognize the massive label spaces to make correct predictions. We evaluate 13 long-context LLMs on our benchmarks. We find that the long-context LLMs perform relatively well on less challenging tasks with shorter demonstration lengths by effectively utilizing the long context window. However, on the most challenging task Discovery with 174 labels, all the LLMs struggle to understand the task definition, thus reaching a performance close to zero. This suggests a notable gap in current LLM capabilities for processing and understanding long, context-rich sequences. Further analysis revealed a tendency among models to favor predictions for labels presented toward the end of the sequence. Their ability to reason over multiple pieces in the long sequence is yet to be improved. Our study reveals that long context understanding and reasoning is still a challenging task for the existing LLMs. We believe LongICLBench could serve as a more realistic evaluation for the future long-context LLMs.
4/5/2024

XL$^2$Bench: A Benchmark for Extremely Long Context Understanding with Long-range Dependencies
Xuanfan Ni, Hengyi Cai, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Piji Li
0
0
Large Language Models (LLMs) have demonstrated remarkable performance across diverse tasks but are constrained by their small context window sizes. Various efforts have been proposed to expand the context window to accommodate even up to 200K input tokens. Meanwhile, building high-quality benchmarks with much longer text lengths and more demanding tasks to provide comprehensive evaluations is of immense practical interest to facilitate long context understanding research of LLMs. However, prior benchmarks create datasets that ostensibly cater to long-text comprehension by expanding the input of traditional tasks, which falls short to exhibit the unique characteristics of long-text understanding, including long dependency tasks and longer text length compatible with modern LLMs' context window size. In this paper, we introduce a benchmark for extremely long context understanding with long-range dependencies, XL$^2$Bench, which includes three scenarios: Fiction Reading, Paper Reading, and Law Reading, and four tasks of increasing complexity: Memory Retrieval, Detailed Understanding, Overall Understanding, and Open-ended Generation, covering 27 subtasks in English and Chinese. It has an average length of 100K+ words (English) and 200K+ characters (Chinese). Evaluating six leading LLMs on XL$^2$Bench, we find that their performance significantly lags behind human levels. Moreover, the observed decline in performance across both the original and enhanced datasets underscores the efficacy of our approach to mitigating data contamination.
4/9/2024