Better & Faster Large Language Models via Multi-token Prediction
2404.19737
299
0
💬
Abstract
Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in higher sample efficiency. More specifically, at each position in the training corpus, we ask the model to predict the following n tokens using n independent output heads, operating on top of a shared model trunk. Considering multi-token prediction as an auxiliary training task, we measure improved downstream capabilities with no overhead in training time for both code and natural language models. The method is increasingly useful for larger model sizes, and keeps its appeal when training for multiple epochs. Gains are especially pronounced on generative benchmarks like coding, where our models consistently outperform strong baselines by several percentage points. Our 13B parameter models solves 12 % more problems on HumanEval and 17 % more on MBPP than comparable next-token models. Experiments on small algorithmic tasks demonstrate that multi-token prediction is favorable for the development of induction heads and algorithmic reasoning capabilities. As an additional benefit, models trained with 4-token prediction are up to 3 times faster at inference, even with large batch sizes.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models like GPT and Llama are typically trained to predict the next token in a sequence.
- This paper suggests that training models to predict multiple future tokens at once can lead to higher sample efficiency and improved downstream capabilities.
- The method involves using multiple independent output heads to predict the next n tokens, operating on a shared model trunk.
- This multi-token prediction task can be used as an auxiliary training objective, with benefits for both code and natural language models.
Plain English Explanation
The paper explores an alternative approach to training large language models like GPT and Llama. Typically, these models are trained to predict the next single token in a sequence, using a "next-token prediction" loss.
However, the researchers propose that training the models to predict multiple future tokens at once can be more effective. Specifically, at each position in the training data, the model is asked to predict the following n tokens using n independent output heads, all built on top of a shared model trunk.
Treating this multi-token prediction as an auxiliary training task, the researchers found that it led to improved downstream capabilities for both code and natural language models, without any increase in training time. The benefits were especially pronounced for generative tasks, like coding, where the multi-token models outperformed strong baselines by several percentage points.
The researchers also found that the multi-token models were up to 3 times faster at inference, even with large batch sizes. This is likely because predicting multiple tokens at once reduces the number of sequential predictions required.
Overall, the key idea is that training language models to look ahead and predict multiple future tokens, rather than just the next one, can lead to significant performance gains across a range of applications.
Technical Explanation
The paper explores an alternative training approach for large language models, where the model is asked to predict multiple future tokens at each position in the training corpus, rather than just the next token.
Specifically, the researchers introduce a "multi-token prediction" objective, where the model uses n independent output heads to predict the next n tokens, all built on top of a shared model trunk. This is treated as an auxiliary training task, in addition to the standard next-token prediction loss.
The researchers evaluate this approach on both code and natural language models, and find consistent improvements in downstream capabilities, with no increase in training time. The gains are especially pronounced on generative benchmarks like coding, where the multi-token models outperform strong baselines by several percentage points.
For example, the researchers' 13B parameter models solve 12% more problems on the HumanEval benchmark and 17% more on the MBPP benchmark, compared to similar-sized next-token models.
The researchers also observe that the multi-token models are significantly faster at inference, up to 3 times faster, even with large batch sizes. This is likely due to the fact that predicting multiple tokens at once reduces the number of sequential predictions required.
Experiments on small algorithmic tasks further demonstrate that the multi-token prediction objective is favorable for the development of induction heads and algorithmic reasoning capabilities.
Overall, the key insight is that training language models to think before they speak, by predicting multiple future tokens instead of just the next one, can lead to substantial performance improvements across a range of applications.
Critical Analysis
The paper presents a compelling approach to training large language models, with clear empirical benefits demonstrated across a range of tasks and benchmarks. The multi-token prediction objective seems to be a simple yet effective way to improve sample efficiency and downstream capabilities, without increasing training time.
However, the paper does not delve into the potential limitations or drawbacks of this approach. For example, it's unclear how the multi-token predictions are used during inference, and whether there are any trade-offs in terms of model complexity or perplexity.
Additionally, the paper focuses primarily on performance metrics, without much discussion of the underlying mechanisms or cognitive capabilities that the multi-token prediction objective might be encouraging. It would be interesting to see further analysis on how this approach affects the model's ability to perform multi-word tokenization or engage in more sophisticated forms of algorithmic reasoning.
Overall, the research presented in this paper is a valuable contribution to the field of large language model training, but further exploration of the approach's limitations and potential implications would be a useful next step.
Conclusion
This paper proposes an innovative training approach for large language models, where the models are trained to predict multiple future tokens at each position in the training corpus, rather than just the next token. The researchers demonstrate that this "multi-token prediction" objective leads to improved sample efficiency and downstream capabilities, with particularly strong gains on generative tasks like coding.
The key insight is that by training models to "think before they speak" and anticipate multiple future tokens, they can develop more sophisticated language understanding and generation abilities. This approach seems to be especially beneficial for larger model sizes and holds up well when training for multiple epochs.
The findings presented in this paper have significant implications for the development of more capable and efficient large language models, which are increasingly important for a wide range of applications in natural language processing and beyond. As the field continues to progress, it will be exciting to see how this and other novel training techniques can push the boundaries of what these models are able to achieve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Is Next Token Prediction Sufficient for GPT? Exploration on Code Logic Comprehension
Mengnan Qi, Yufan Huang, Yongqiang Yao, Maoquan Wang, Bin Gu, Neel Sundaresan
0
0
Large language models (LLMs) has experienced exponential growth, they demonstrate remarkable performance across various tasks. Notwithstanding, contemporary research primarily centers on enhancing the size and quality of pretraining data, still utilizing the next token prediction task on autoregressive transformer model structure. The efficacy of this task in truly facilitating the model's comprehension of code logic remains questionable, we speculate that it still interprets code as mere text, while human emphasizes the underlying logical knowledge. In order to prove it, we introduce a new task, Logically Equivalent Code Selection, which necessitates the selection of logically equivalent code from a candidate set, given a query code. Our experimental findings indicate that current LLMs underperform in this task, since they understand code by unordered bag of keywords. To ameliorate their performance, we propose an advanced pretraining task, Next Token Prediction+. This task aims to modify the sentence embedding distribution of the LLM without sacrificing its generative capabilities. Our experimental results reveal that following this pretraining, both Code Llama and StarCoder, the prevalent code domain pretraining models, display significant improvements on our logically equivalent code selection task and the code completion task.
4/16/2024
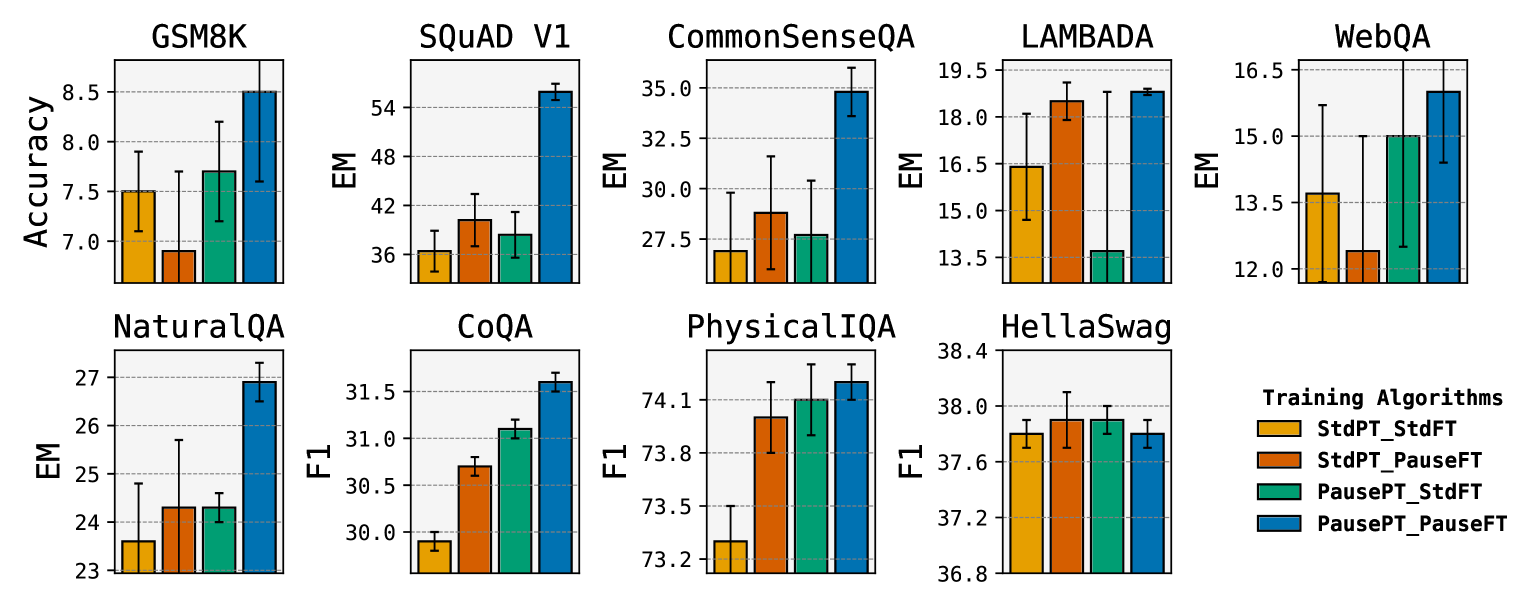
Think before you speak: Training Language Models With Pause Tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, Vaishnavh Nagarajan
0
0
Language models generate responses by producing a series of tokens in immediate succession: the $(K+1)^{th}$ token is an outcome of manipulating $K$ hidden vectors per layer, one vector per preceding token. What if instead we were to let the model manipulate say, $K+10$ hidden vectors, before it outputs the $(K+1)^{th}$ token? We operationalize this idea by performing training and inference on language models with a (learnable) $textit{pause}$ token, a sequence of which is appended to the input prefix. We then delay extracting the model's outputs until the last pause token is seen, thereby allowing the model to process extra computation before committing to an answer. We empirically evaluate $textit{pause-training}$ on decoder-only models of 1B and 130M parameters with causal pretraining on C4, and on downstream tasks covering reasoning, question-answering, general understanding and fact recall. Our main finding is that inference-time delays show gains when the model is both pre-trained and finetuned with delays. For the 1B model, we witness gains on 8 of 9 tasks, most prominently, a gain of $18%$ EM score on the QA task of SQuAD, $8%$ on CommonSenseQA and $1%$ accuracy on the reasoning task of GSM8k. Our work raises a range of conceptual and practical future research questions on making delayed next-token prediction a widely applicable new paradigm.
4/23/2024

DynaMo: Accelerating Language Model Inference with Dynamic Multi-Token Sampling
Shikhar Tuli, Chi-Heng Lin, Yen-Chang Hsu, Niraj K. Jha, Yilin Shen, Hongxia Jin
0
0
Traditional language models operate autoregressively, i.e., they predict one token at a time. Rapid explosion in model sizes has resulted in high inference times. In this work, we propose DynaMo, a suite of multi-token prediction language models that reduce net inference times. Our models $textit{dynamically}$ predict multiple tokens based on their confidence in the predicted joint probability distribution. We propose a lightweight technique to train these models, leveraging the weights of traditional autoregressive counterparts. Moreover, we propose novel ways to enhance the estimated joint probability to improve text generation quality, namely co-occurrence weighted masking and adaptive thresholding. We also propose systematic qualitative and quantitative methods to rigorously test the quality of generated text for non-autoregressive generation. One of the models in our suite, DynaMo-7.3B-T3, achieves same-quality generated text as the baseline (Pythia-6.9B) while achieving 2.57$times$ speed-up with only 5.87% and 2.67% parameter and training time overheads, respectively.
5/3/2024
📶
Can Perplexity Predict Fine-Tuning Performance? An Investigation of Tokenization Effects on Sequential Language Models for Nepali
Nishant Luitel, Nirajan Bekoju, Anand Kumar Sah, Subarna Shakya
0
0
Recent language models use subwording mechanisms to handle Out-of-Vocabulary(OOV) words seen during test time and, their generation capacity is generally measured using perplexity, an intrinsic metric. It is known that increasing the subword granularity results in a decrease of perplexity value. However, the study of how subwording affects the understanding capacity of language models has been very few and only limited to a handful of languages. To reduce this gap we used 6 different tokenization schemes to pretrain relatively small language models in Nepali and used the representations learned to finetune on several downstream tasks. Although byte-level BPE algorithm has been used in recent models like GPT, RoBERTa we show that on average they are sub-optimal in comparison to algorithms such as SentencePiece in finetuning performances for Nepali. Additionally, similar recent studies have focused on the Bert-based language model. We, however, pretrain and finetune sequential transformer-based language models.
4/30/2024